.
Définitions des statistiques >
Qu’est-ce que l’échelle de Likert ?
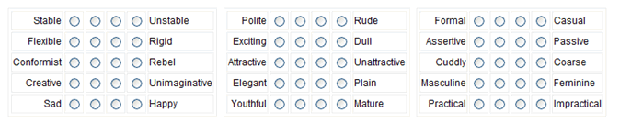
Variations de l’échelle de Likert.
Une échelle de Likert est un type d’échelle d’évaluation utilisé pour mesurer les attitudes ou les opinions. Avec cette échelle, on demande aux répondants de noter les éléments selon un niveau d’accord. Par exemple :
- Très d’accord
- En accord
- Neutre
- Désaccord
- Très en désaccord
Cinq à sept items sont généralement utilisés dans l’échelle. L’échelle ne doit pas nécessairement indiquer » d’accord » ou » pas d’accord » ; des dizaines de variations sont possibles sur des thèmes comme l’accord, la fréquence, la qualité et l’importance. Par exemple :
- Accord : Fortement d’accord à fortement en désaccord.
- Fréquence : Souvent à jamais.
- Qualité : Très bonne à très mauvaise.
- Vraisemblance : Certainement à jamais.
- Importance : Très important à peu important.
Ces items sont appelés ancres de réponse de l’échelle de Likert.
Une fois que les personnes interrogées ont répondu, des numéros sont attribués aux réponses. Par exemple :
Consentement fort=5
Accord=4
Neutre=3
Désaccord=2
Désaccord fort=1
Cela vous permet d’attribuer une signification aux réponses. Par exemple, une enquête sur le service client peut vous permettre de voir lesquels de vos représentants du service client fournissent un bon service (note moyenne de 4-5) et lesquels fournissent un mauvais service (note moyenne de 1-2).
Étapes de l’élaboration d’une échelle de Likert
- Définir le sujet : qu’est-ce que vous essayez de mesurer ? Votre sujet doit être unidimensionnel. Par exemple, » le service client » ou » ce site Web « .
- Générer les items de l’échelle de Likert. Les items doivent pouvoir être notés sur une sorte d’échelle. L’image en haut de cette page a quelques suggestions. Par exemple, la politesse/l’impolitesse pourrait être notée comme « très polie », « polie », « pas polie » ou « très impolie. » La politesse pourrait également être notée sur une échelle de 1 à 10, où 1 est pas du tout poli et 10 est extrêmement poli.
- Notez les éléments de l’échelle de Likert. Vous voulez être sûr que votre objectif est bon, alors choisissez une équipe de personnes pour passer en revue les éléments de l’étape 2 ci-dessus et les noter comme favorables/neutres/défavorables à votre objectif. Éliminez les éléments qui sont surtout considérés comme défavorables.
- Administrez votre test sur l’échelle de Likert.
Tests d’hypothèse sur les échelles de Likert
Si vous saviez que vous allez effectuer une analyse sur les données de l’échelle de Likert, il est plus facile d’adapter vos questions au stade de l’élaboration, plutôt que de recueillir vos données et de prendre ensuite une décision sur l’analyse. L’analyse que vous effectuez dépend du format de votre questionnaire.
Il existe un certain désaccord dans l’enseignement et la recherche sur la question de savoir si vous devez effectuer des tests paramétriques comme le test t ou des tests d’hypothèse non paramétriques comme le Mann-Whitney sur des données d’échelle de Likert. Winter et Dodou(2010) ont étudié cette question, avec les résultats suivants:
« En conclusion, le test t et ont généralement une puissance équivalente, sauf pour les distributions asymétriques, à crête ou multimodales pour lesquelles de fortes différences de puissance entre les deux tests sont apparues. Le taux d’erreur de type I des deux méthodes n’a jamais dépassé de plus de 3 % le taux nominal de 5 %, même pas lorsque les tailles d’échantillon étaient très inégales. »
En d’autres termes, il ne semble pas y avoir de réelle différence entre les résultats des tests paramétriques et non paramétriques, sauf pour les distributions asymétriques, à pics ou multimodales. Le choix de la voie à suivre dépend de vous, de votre département et peut-être de la revue à laquelle vous soumettez votre article (le cas échéant). L’étape la plus importante au stade de la décision est de décider si vous voulez traiter vos données comme des données ordinales ou des données d’intervalle. Ensuite, lisez la section ci-dessous pour votre type de données. Quelques directives générales :
- Pour une série de questions individuelles avec des réponses de Likert, traitez les données comme des variables ordinales.
- Pour une série de questions de Likert qui décrivent ensemble un seul construit (trait de personnalité ou attitude), traitez les données comme des variables d’intervalle.
Deux options
La plupart des échelles de Likert sont classées comme des variables ordinales. Si vous êtes sûr à 100% que la distance entre les variables est constante, alors elles peuvent être traitées comme des variables d’intervalle à des fins de test. Dans la plupart des cas, vos données seront ordinales, car il est impossible de faire la différence entre, par exemple, « tout à fait d’accord » et « d’accord » par rapport à « d’accord » et « neutre ».
Données d’échelle ordinale
Avec la plupart des types de variables (intervalle, rapport, nominal), vous pouvez trouver la moyenne. Ce n’est pas le cas pour les données de l’échelle de Likert. La moyenne dans une échelle de Likert ne peut pas être trouvée parce que vous ne connaissez pas la » distance » entre les éléments de données. En d’autres termes, si vous pouvez trouver une moyenne de 1,2 et 3, vous ne pouvez pas trouver une moyenne de « d’accord », « pas d’accord » et « neutre ».
« La moyenne de « passable » et « bon » n’est pas « passable-et-demi » ; ce qui est vrai même lorsqu’on attribue des nombres entiers pour représenter « passable » et « bon » ! » – Susan Jamieson paraphrasant Kuzon Jr et al. (Jamieson, 2004)
Choix des statistiques
Les statistiques que vous pouvez utiliser sont :
- Le mode : la réponse la plus courante.
- La médiane : la réponse » moyenne » lorsque tous les éléments sont placés dans l’ordre.
- L’étendue et l’écart interquartile : pour montrer la variabilité.
- Un histogramme ou un tableau de fréquence : pour montrer un tableau de résultats. Ne faites pas d’histogramme, car les données ne sont pas continues.
Test d’hypothèse
Dans le test d’hypothèse pour les échelles de Likert, la variable indépendante représente les groupes et la variable dépendante représente le construit que vous mesurez. Par exemple, si vous interrogez des étudiants en soins infirmiers pour mesurer leur niveau de compassion, la variable indépendante est les groupes d’étudiants en soins infirmiers et la variable dépendante est le niveau de compassion.
Types de tests que vous pouvez effectuer :
- Kruskal Wallis : détermine si la médiane de deux groupes est différente.
- Test U de Mann Whitney : détermine si les médianes de deux groupes sont différentes. Simple à évaluer les questions à échelle de Likert unique, mais souffre de plusieurs formes de biais, notamment le biais de tendance centrale, le biais d’acquiescement et le biais de désirabilité sociale. En outre, la validité est généralement difficile à démontrer.
Plus d’options pour deux catégories
Si vous combinez vos réponses en deux catégories, par exemple, d’accord et pas d’accord, plus d’options de test s’ouvrent à vous.
- Khi-deux : Ce test est conçu pour les expériences multinomiales, où les résultats sont des comptes placés dans des catégories.
- Test de McNemar : Teste si les réponses aux catégories sont les mêmes pour deux groupes/conditions.
- Test Q de Cochran : Une extension de McNemar qui teste si les réponses aux catégories sont les mêmes pour trois groupes/conditions ou plus.
- Test de Friedman : pour trouver des différences dans les traitements entre plusieurs tentatives.
Mesures d’association
Parfois, vous voulez savoir si un groupe de personnes a une réponse différente (plus élevée ou plus faible) d’un autre groupe de personnes à un certain élément de l’échelle de Likert. Pour répondre à cette question, vous utiliserez une mesure d’association au lieu d’un test de différences (comme ceux énumérés ci-dessus).
Si vos groupes sont ordinaux (c’est-à-dire ordonnés) d’une manière ou d’une autre, comme les groupes d’âge, vous pouvez utiliser :
- Le coefficient tau de Kendall ou des variantes de tau (par exemple, le coefficient gamma ; le D de Somers).
- Corrélation de rang de Spearman.
Si vos groupes ne sont pas ordinaux, alors utilisez l’un de ceux-ci :
- Coefficient Phi.
- Coefficient de contingence.
- V de Cramer.
Données à échelle d’intervalle
Statistiques qui conviennent aux données Likert à échelle d’intervalle:
- Moyenne.
- Écart-type.
Tests d’hypothèse adaptés aux données Likert à échelle d’intervalle :
- Test T.
- ANOVA.
- Analyse de régression (régression logistique ordonnée ou régression logistique multinomiale). Si vous pouvez combiner vos variables dépendantes en deux réponses (par exemple, d’accord ou pas d’accord), exécutez une régression logistique binaire.
——————————————————————————
Vous avez besoin d’aide pour un devoir ou une question de test ? Avec Chegg Study, vous pouvez obtenir des solutions étape par étape à vos questions de la part d’un expert dans le domaine. Vos 30 premières minutes avec un tuteur Chegg sont gratuites !