Par Noel Bambrick, AYLIEN.
Introduction
Dans ce post, nous allons vous présenter l’algorithme d’apprentissage automatique Support Vector Machine (SVM). Nous suivrons un processus similaire à celui de notre récent post Naive Bayes pour les nuls ; une explication simple en restant court et pas trop technique. L’objectif est de donner à ceux d’entre vous qui sont nouveaux dans l’apprentissage automatique une compréhension de base des concepts clés de cet algorithme.
Les machines à vecteurs de support – Qu’est-ce que c’est ?
Une machine à vecteurs de support (SVM) est un algorithme d’apprentissage automatique supervisé qui peut être employé à des fins de classification et de régression. Les SVM sont plus couramment utilisés dans les problèmes de classification et, à ce titre, c’est ce sur quoi nous allons nous concentrer dans ce post.
Les SVM sont basés sur l’idée de trouver un hyperplan qui divise le mieux un ensemble de données en deux classes, comme le montre l’image ci-dessous.
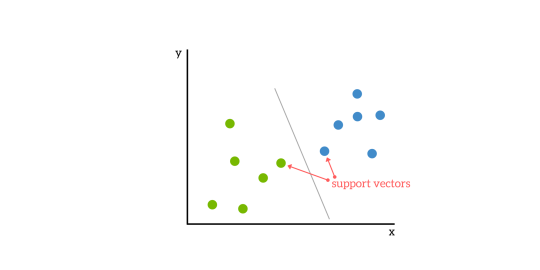
Vecteurs de support
Les vecteurs de support sont les points de données les plus proches de l’hyperplan, les points d’un ensemble de données qui, s’ils étaient supprimés, modifieraient la position de l’hyperplan de division. Pour cette raison, ils peuvent être considérés comme les éléments critiques d’un ensemble de données.
Qu’est-ce qu’un hyperplan ?
À titre d’exemple simple, pour une tâche de classification avec seulement deux caractéristiques (comme l’image ci-dessus), vous pouvez considérer un hyperplan comme une ligne qui sépare et classifie linéairement un ensemble de données.
Intuitivement, plus nos points de données sont éloignés de l’hyperplan, plus nous sommes sûrs qu’ils ont été correctement classés. Nous voulons donc que nos points de données soient aussi éloignés de l’hyperplan que possible, tout en étant du bon côté de celui-ci.
Donc, lorsque de nouvelles données de test sont ajoutées, le côté de l’hyperplan qu’elles atterrissent décide de la classe que nous leur attribuons.
Comment trouver le bon hyperplan ?
Ou, en d’autres termes, comment séparer au mieux les deux classes au sein des données ?
La distance entre l’hyperplan et le point de données le plus proche de l’un ou l’autre ensemble est appelée la marge. L’objectif est de choisir un hyperplan avec la plus grande marge possible entre l’hyperplan et n’importe quel point de l’ensemble d’entraînement, ce qui donne une plus grande chance que les nouvelles données soient classées correctement.
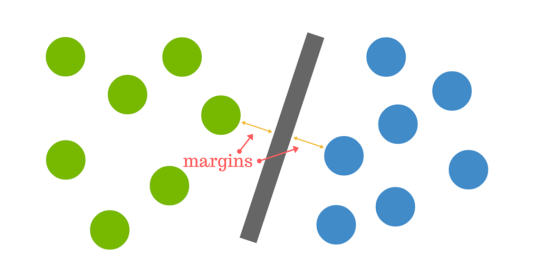
Mais que se passe-t-il lorsqu’il n’y a pas d’hyperplan clair ?
C’est là que cela peut devenir délicat. Les données sont rarement aussi propres que notre exemple simple ci-dessus. Un ensemble de données ressemblera souvent plus aux boules mélangées ci-dessous qui représentent un ensemble de données linéairement non séparables.
 ici.
ici.
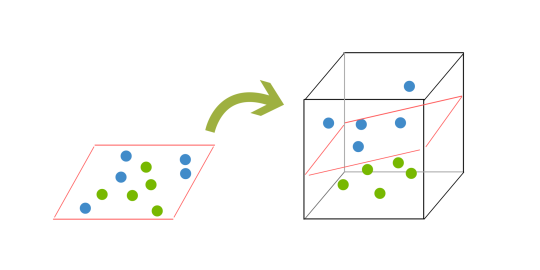
Parce que nous sommes maintenant en trois dimensions, notre hyperplan ne peut plus être une ligne. Il doit maintenant être un plan comme le montre l’exemple ci-dessus. L’idée est que les données vont continuer à être cartographiées dans des dimensions de plus en plus élevées jusqu’à ce qu’un hyperplan puisse être formé pour les séparer.
Pros & Inconvénients des machines à vecteurs de support
Pros
- Accuracy
- Work well on smaller cleaner datasets
- Il peut être plus efficace car il utilise un sous-ensemble de points d’entraînement
Cons
.
- Il n’est pas adapté aux grands ensembles de données car le temps d’apprentissage avec les SVM peut être élevé
- Moins efficace sur les ensembles de données plus bruyants avec des classes qui se chevauchent
Utilisations des SVM
Les SVM sont utilisés pour des tâches de classification de texte telles que l’affectation de catégories, la détection du spam et l’analyse des sentiments. Il est également couramment utilisé pour les défis de reconnaissance d’images, performant particulièrement bien dans la reconnaissance basée sur les aspects et la classification basée sur les couleurs. Le SVM joue également un rôle essentiel dans de nombreux domaines de la reconnaissance des chiffres manuscrits, tels que les services d’automatisation postale.
Voilà, une introduction de très haut niveau aux machines à vecteurs de support. Si vous souhaitez plonger plus profondément dans les SVM, nous vous recommandons de consulter (besoin de trouver un lien vers une vidéo ou un blog plus approfondi).
A propos de : Ce blog a été initialement publié sur le blog d’analyse de texte AYLIEN. AYLIEN fournit des outils et des services pour aider les développeurs et les scientifiques des données à donner un sens au contenu non structuré à l’échelle.
Original. Reposé avec permission.
Relié:
- Comment sélectionner les noyaux de machine à vecteur de support
- Quand l’apprentissage profond fonctionne-t-il mieux que les SVM ou les forêts aléatoires ?
- Termes clés de l’apprentissage automatique, expliqués
.