Het ding over mij is dat ik Joods ben. Dat is niet het enige aan mij. Ik ben ook 1,80 m lang, brildragend en fiets graag. Maar de meeste mensen die mij kennen, zouden waarschijnlijk niet verbaasd zijn te horen dat de meeste van mijn voorouders in shtetls in Oost-Europa woonden.
Dus was het niet al te verrassend toen ik negen DNA-monsters naar drie verschillende DNA-bedrijven stuurde onder verschillende valse namen, en de resultaten aangaven dat ik super-duper Ashkenazi Joods ben. (Asjkenazim zijn Joden die hun voorouders terugvoeren tot Jiddisj-sprekende bevolkingsgroepen die de regio tussen Frankrijk en Rusland bewoonden.)
Hier is wat wel een beetje verrassend was: Geen van de bedrijven – AncestryDNA, 23andMe en National Geographic, dat samenwerkt met een testbedrijf dat Helix heet – kon het eens worden over hoe Ashkenazisch ik ben.
Drie bedrijven, drie fouten en zes verschillende resultaten
AncestryDNA
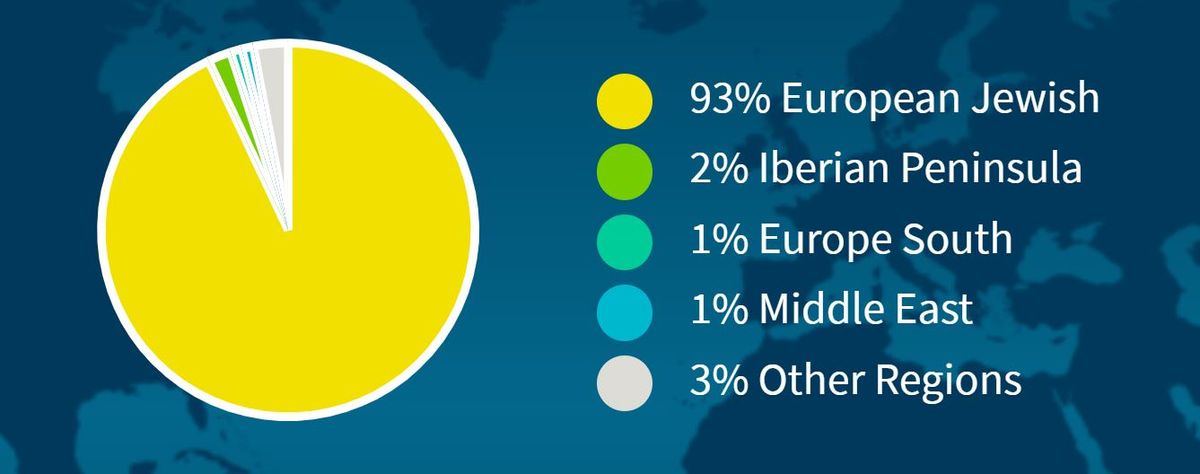
AncestryDNA bekeek het eerste DNA-monster dat Live Science voor me opstuurde en meldde terug dat ik voor 93 procent “Europees Joods” ben. De rest van mijn voorouders, zo suggereerde het rapport, is als volgt: 2 procent gaat terug tot het Iberisch Schiereiland (dat zijn Spanje en Portugal); 1 procent gaat terug tot het “Europese Zuiden”; 1 procent gaat terug tot het Midden-Oosten; en de rest komt van elders.
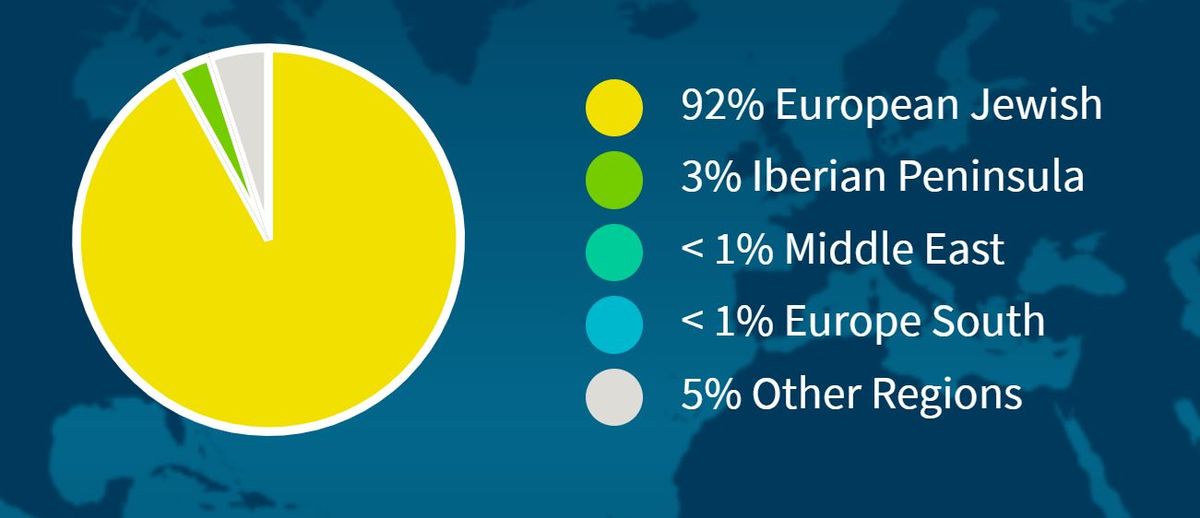
De tweede steekproef leverde vergelijkbare – maar, interessant genoeg, niet identieke – resultaten op. Dit stukje Rafi-spuug-in-een-buisje, zo meldde het rapport, was slechts voor 92 procent Asjkenazisch, maar voor 3 procent Iberisch. De rest van het DNA kan volgens Ancestry teruggaan op het Midden-Oosten, het Europese Zuiden of andere regio’s. Maar elk van die bronnen vertegenwoordigde, volgens de site, hooguit minder dan 1 procent van mijn DNA.
(Live Science heeft een derde monster van mijn DNA naar Ancestry gestuurd onder een derde naam, maar door een fout hebben we geen toegang tot de resultaten.
23andMe
Net als AncestryDNA concludeerde 23andMe uit het eerste DNA-monster dat mijn Ashkenaziness ergens in de lage 90-er jaren ligt, met een klein verschil tussen elk van de monsters die het ontving. In tegenstelling tot AncestryDNA, had het een niet geheel oude wereld interpretatie van waar mijn voorouders vandaan zouden kunnen komen – suggererend dat misschien een fractie van 1 procent van mijn voorouders Indisch Amerikaans waren. (Gezien wat ik van mijn familiegeschiedenis weet, is dit vrijwel zeker niet waar.)
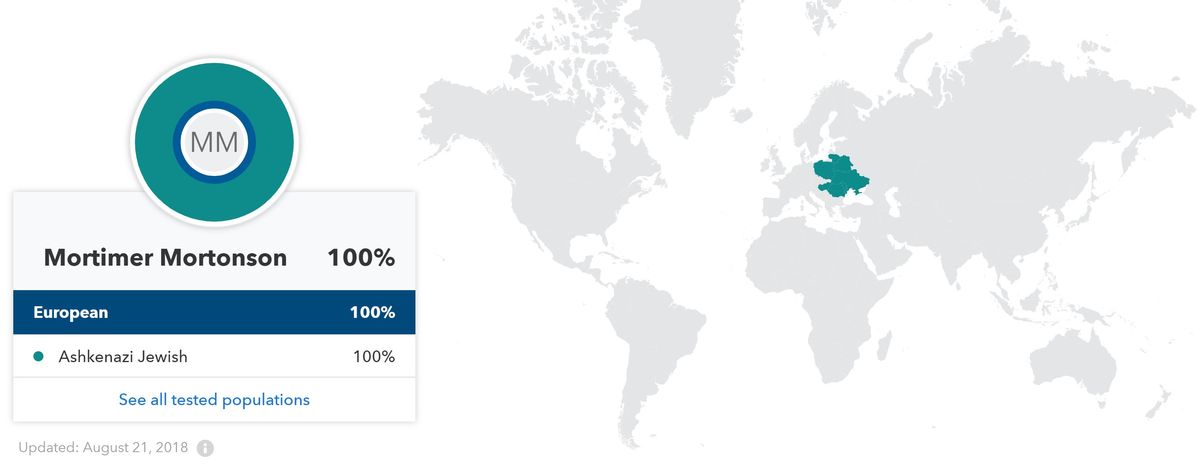
Terwijl ik verslag deed van dit verhaal, heeft 23andMe zijn systeem voor het interpreteren van DNA-monsters geactualiseerd en al het DNA dat al in het systeem zit, opnieuw beoordeeld. Wanneer ik nu bij 23andMe inlog met de drie verschillende namen die ik heb gegeven, zeggen de rapporten voor twee van die namen dat ik 100 procent Asjkenazische voorouders heb.
(Een derde monster dat naar 23andMe is gestuurd, heeft geen resultaten opgeleverd. Live Science kende de naam van een vrouw toe aan een van de monsters die het naar elk bedrijf stuurde en markeerde het geslacht als vrouwelijk. AncestryDNA verwerkte het “vrouwelijke” monster prima, zonder enige indicatie van iets onverwachts, maar zowel 23andMe als Nat Geo eisten meer persoonlijke informatie alvorens verder te gaan, omdat het afkomstig was van een persoon met onverwachte chromosomen.)
Nat Geo en Helix
Tot slot is er Nat Geo, dat een dienst genaamd Helix gebruikt om DNA-tests uit te voeren. Helix verwerkt het ruwe DNA, terwijl Nat Geo de interpretatie voor zijn rekening neemt.
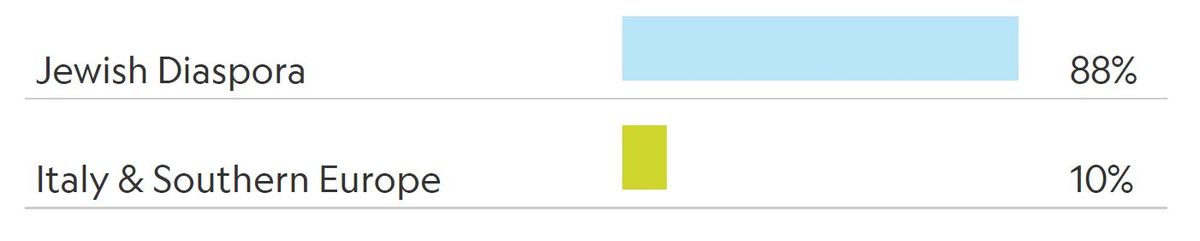
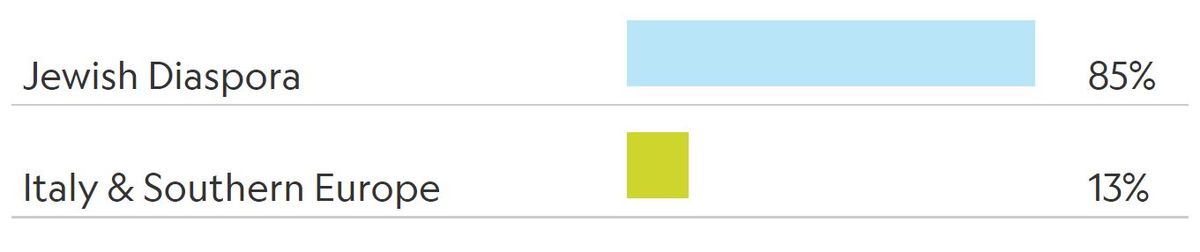
Volgens Nat Geo ben ik veel minder dan 100% Asjkenazisch. De genetische dienst meldde dat de voorouders van mijn eerste monster voor 88 procent afkomstig waren uit de “Joodse Diaspora” (in deze context een term die min of meer verwijst naar Asjkenaziem) en voor 10 procent uit “Italië en Zuid-Europa.”
Nat Geo meldde ook het grootste verschil tussen zijn twee succesvolle steekproeven, door te melden dat de tweede steekproef die het ontving 3 procent minder “Joodse Diaspora” was dan de eerste – slechts 85 procent. De rest was deze keer 13 procent “Italië en Zuid-Europa.”
Dus, negen DNA-tests later, weet ik het volgende over mezelf: Ik ben heel erg Asjkenazisch Joods. Voornamelijk. Of helemaal. De rest van mijn voorouders in het recente verleden heeft waarschijnlijk ook in Europa gewoond – maar wie weet waar. En misschien was er ergens in mijn stamboom een Midden-Oosterling, of een Indiaan. Maar waarschijnlijk (bijna zeker) niet.
Maar dat wist ik natuurlijk allemaal al.
The Science
Wetenschappers die gespecialiseerd zijn in dit soort onderzoek vertelden Live Science dat dit allemaal niet zo verrassend is, hoewel ze opmerkten dat het feit dat de bedrijven niet eens consistente resultaten konden produceren van monsters die van dezelfde persoon waren genomen een beetje vreemd was.
“Voorouders zelf zijn een grappig iets, in die zin dat mensen nooit deze verschillende groepen mensen zijn geweest,” zei Alexander Platt, een expert in populatiegenetica aan de Temple University in Philadelphia. “Je kunt dus niet echt zeggen dat iemand voor 92,6 procent afstamt van deze groep mensen, terwijl dat eigenlijk niet bestaat.”
Ga naar een website als die van Nat Geo en de wereld wordt in verschillende stukken opgedeeld. Sommige van je voorouders kwamen van deze plek, zegt hij, en zij waren Centraal Aziatisch. Anderen kwamen van die plek daar, en zij waren Midden-Oosten. Maar dat is niet hoe de menselijke geschiedenis eruit ziet. Populaties groeien samen. Mensen trekken rond, komen samen en gaan weer uit elkaar. Iemand die zichzelf nu Italiaan noemt, kan een paar duizend jaar geleden Galliër zijn geweest en ten strijde zijn getrokken tegen de Romeinen.
Om mensen in groepen in te delen, zo vertelde Platt aan Live Science, nemen onderzoekers beslissingen: Ze zullen bijvoorbeeld zeggen: de leden van deze groep mensen hebben allemaal ten minste enkele generaties in Marokko gewoond, dus voegen we hun DNA toe aan de referentiebibliotheken voor Marokkanen. En mensen die één grootouder hadden met dat soort DNA zullen te horen krijgen dat ze voor 25 procent Marokkaans zijn. Maar die grens, zei Platt, is fundamenteel “denkbeeldig.”
“Er zit structuur in de geschiedenis,” zei hij. “Bepaalde volkeren zijn nauwer met elkaar verwant dan met andere volkeren. En proberen binnen die clusters grenzen te creëren. Maar die grenzen hebben nooit echt bestaan, en het zijn ook geen echte dingen.”
Op sommige plaatsen is dat gemakkelijker. Niet-Joodse Europese bevolkingsgroepen, zei hij, mengen zich niet zo veel met anderen als mensen elders in de wereld, dus bedrijven kunnen gemakkelijk een fijner onderscheid tussen hen maken.
Maar uiteindelijk betekent het niets als je 35 procent Iers bent, of 76 procent Fins. Dus toen 23andMe van gedachten veranderde over mijn voorouders, was het antwoord van 100 procent niet meer waar. Het was gewoon een andere manier om de gegevens te interpreteren.
(In dit geval, zei Platt, heeft het bedrijf waarschijnlijk besloten dat, omdat bijna alle Asjkenazische Joden een aantal genen gemeen hebben met een mix van andere Europese bevolkingsgroepen, het logisch is om die genen ook Asjkenazisch te noemen.)
“Het is niet zozeer wetenschap als wel een beschrijving,” zei hij. “Er is hier niet echt een goed of fout antwoord, omdat er geen officiële aanduiding is van wat het betekent om genetisch gezien Asjkenazisch Joods te zijn.”
Het is voor hem niet echt vreemd dat er een verschil van 15 procent Joodsheid is tussen mijn resultaten in Nat Geo en in 23andMe, zei hij.

Mark Stoneking, een populatiegeneticus en groepsleider aan het Max Planck Instituut voor Evoluntionaire Antropologie in Leipzig, Duitsland, was het daarmee eens.
“Als ze helemaal eerlijk zouden zijn, zouden ze je niet moeten vertellen dat je 47 procent Italiaans bent, maar dat je 47 bent plus of min een foutenmarge … gebaseerd op hun vermogen om deze afstamming te onderscheiden en andere bronnen van fouten die in de schatting zitten,” vertelde Stoneking aan Live Science.
En het is duidelijk dat er bronnen van fouten zijn, zei hij. Stoneking noch Platt wist precies waarom AncestryDNA een verschil van 1 procent had tussen zijn resultaten voor verschillende monsters, of Nat Geo een verschil van 3 procent had, of 23andMe een speelruimte had die verdween met de update. Maar ze waren het erover eens dat het waarschijnlijk iets te maken heeft met hun methoden om een flesje spuug om te zetten in gegevens die de computer kan interpreteren. (Live Science vroeg alle drie bedrijven om het probleem uit te leggen, maar geen van hen gaf een specifiek antwoord).
Elk van deze bedrijven, aldus Stoneking, splitst het DNA in het spuugmonster op in allelen – genetische markers die zij als ruwe gegevens gebruiken. Maar dat proces is onvolmaakt en werkt duidelijk niet op dezelfde manier elke keer dat de bedrijven de tests uitvoeren, zei hij – hoewel de fouten niet enorm significant zijn.
Moet je je DNA laten testen?
Niets van dit alles betekent dat een voorouderkit van 23andMe of AncestryDNA of Nat Geo waardeloos is, waren Stoneking en Platt het erover eens.
“Ik zie deze dingen meer als vermaak dan als iets anders,” zei Stoneking.
De echte wetenschap van de populatiegenetica, legde hij uit, wordt gebruikt om erachter te komen hoe grote groepen mensen zich in de loop der tijd hebben verplaatst en vermengd. En voor dat doel is het goed. Maar uitzoeken of 3 tot 13 procent van mijn voorouders van het Iberisch schiereiland of Italië afkomstig is, maakt geen deel uit van dat project.
Platt zei dat hij zich commercieel had laten testen, en dat hij weliswaar niets verrassends had gevonden, maar dat het voor iemand altijd mogelijk is iets nieuws en interessants te leren – vooral als hij van niet-joods-Europese afkomst is en vaag over de details. Een blanke niet-jood kan iets specifieks en interessants te weten komen over zijn achtergrond, omdat zijn voorouders waarschijnlijk afkomstig zijn van zeer geïsoleerde referentiepopulaties waarover de bedrijven veel gegevens hebben. Maar mensen uit andere plaatsen hebben lagere kansen, simpelweg omdat de gegevens uit andere plaatsen beperkter, vager en moeilijker te interpreteren zijn.
Toen ik contact opnam met de bedrijven en hen vroeg om commentaar te geven op dit verhaal en in te gaan op de vraag waarom mijn resultaten kunnen verschillen – zelfs wanneer de test werd uitgevoerd door hetzelfde bedrijf – reageerden zowel Ancestry als 23andMe.
Hier is wat Ancestry zei:
“We zijn vol vertrouwen in de wetenschap en de resultaten die we aan klanten geven. De genomica-industrie voor consumenten staat nog in de kinderschoenen, maar groeit snel en we vertellen klanten tijdens de hele ervaring dat hun resultaten zo nauwkeurig mogelijk zijn voor waar de wetenschap vandaag staat, en dat het in de loop van de tijd kan evolueren naarmate de resolutie van DNA-schattingen verbetert. We zullen er altijd naar streven om ontwikkelingen in de wetenschap aan te grijpen om de ervaring van onze klanten te verbeteren. Recente ontwikkelingen in de DNA-wetenschap hebben ons bijvoorbeeld in staat gesteld een nieuw algoritme te ontwikkelen dat de etnische uitsplitsing van klanten met een hogere mate van precisie bepaalt.”
En hier is het commentaar van 23andMe, dat de vertegenwoordiger Live Science verzocht toe te schrijven aan Robin Smith, een Ph.D. die de titel van groepsprojectmanager bij het bedrijf bekleedt:
“Onze voorouderrapporten zijn een levende analyse en zijn voortdurend in ontwikkeling, en naarmate onze database groeit, zullen we in staat zijn om klanten meer granulaire informatie te geven over hun voorouders en etniciteit. We zijn voortdurend bezig met het verbeteren van zowel onze referentie datasets, als de algemene pijplijn die we gebruiken om de Ancestry Composition rapporten van klanten te berekenen. Eerder dit jaar hebben we zelfs een uitgebreide voorouderupdate uitgerold, waarbij we het aantal landen en regio’s waarover we rapporteren hebben uitgebreid – om meer diepgaande informatie te kunnen verstrekken aan bevolkingsgroepen die ondervertegenwoordigd zijn in de studie van genetica.
“Met betrekking tot de Ashkenazi-referentiepopulaties is onze precisie voor het noemen van de AJ-voorouders de afgelopen twee jaar inderdaad verbeterd van 97 procent naar 99 procent, om deze redenen. Onze recall, d.w.z. hoeveel van alle Asjkenazische Joodse voorouders in de dataset we AJ noemen, is verbeterd tot 97 procent, tegen 93 procent twee jaar geleden.