Door Noel Bambrick, AYLIEN.
Inleiding
In dit bericht gaan we u kennis laten maken met het Support Vector Machine (SVM) machine learning algoritme. We zullen een vergelijkbaar proces volgen als onze recente post Naive Bayes voor Dummies; Een eenvoudige uitleg door het kort en niet overdreven technisch te houden. Het doel is om degenen die nieuw zijn in machine learning een basisbegrip te geven van de belangrijkste concepten van dit algoritme.
Support Vector Machines – Wat zijn het?
Een Support Vector Machine (SVM) is een machine learning algoritme dat kan worden gebruikt voor zowel classificatie- als regressiedoeleinden. SVM’s worden vaker gebruikt bij classificatieproblemen, en daar zullen we ons in dit artikel dan ook op richten.
SVM’s zijn gebaseerd op het idee om een hypervlak te vinden dat een dataset het beste verdeelt in twee klassen, zoals te zien is in de onderstaande afbeelding.
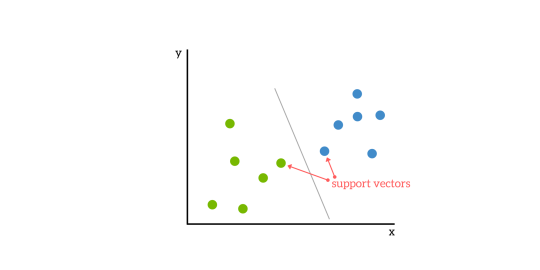
Support Vectors
Support vectors zijn de datapunten die het dichtst bij het hypervlak liggen, de punten van een dataset die, als ze zouden worden verwijderd, de positie van het scheidende hypervlak zouden veranderen. Daarom kunnen ze worden beschouwd als de kritische elementen van een dataset.
Wat is een hypervlak?
Een eenvoudig voorbeeld, voor een classificatietaak met slechts twee kenmerken (zoals de afbeelding hierboven), kun je een hypervlak zien als een lijn die een verzameling gegevens lineair scheidt en classificeert.
Intuïtief: hoe verder onze datapunten van het hypervlak afliggen, hoe zekerder we zijn dat ze juist zijn geclassificeerd. Daarom willen we dat onze datapunten zo ver mogelijk van het hypervlak liggen, maar nog wel aan de juiste kant
Dus als er nieuwe testgegevens worden toegevoegd, wordt de klasse die we eraan toekennen bepaald door de kant van het hypervlak waar ze terechtkomen.
Hoe vinden we het juiste hypervlak?
Of, met andere woorden, hoe kunnen we de twee klassen binnen de gegevens het beste scheiden?
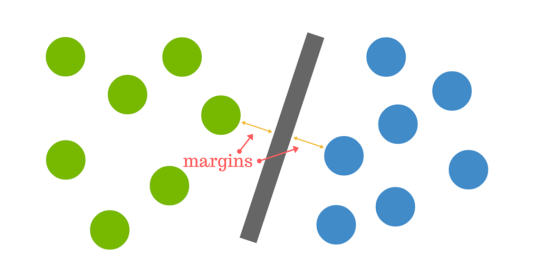
De afstand tussen het hypervlak en het dichtstbijzijnde gegevenspunt uit een van beide sets staat bekend als de marge. Het doel is een hypervlak te kiezen met de grootst mogelijke marge tussen het hypervlak en elk punt in de trainingsset, zodat de kans groter is dat nieuwe gegevens correct worden geclassificeerd.
Maar wat gebeurt er als er geen duidelijk hypervlak is?
Dit is waar het lastig kan worden. Data is zelden zo schoon als ons eenvoudige voorbeeld hierboven. Een dataset zal er vaak meer uitzien als de warrige bolletjes hieronder, die een lineair niet-scheidbare dataset voorstellen.
 hier.
hier.
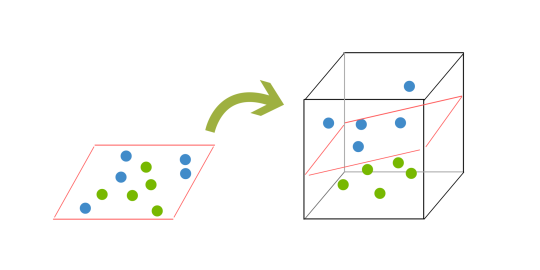
Omdat we nu in drie dimensies zijn, kan ons hypervlak niet langer een lijn zijn. Het moet nu een vlak zijn, zoals in het voorbeeld hierboven. Het idee is dat de gegevens in steeds hogere dimensies in kaart worden gebracht totdat een hypervlak kan worden gevormd dat de gegevens scheidt.
Pros & Nadelen van Support Vector Machines
Pros
- Nauwkeurigheid
- Werkt goed op kleinere schonere datasets
- Het kan efficiënter zijn omdat het een subset van trainingspunten gebruikt
Cons
- Is niet geschikt voor grotere datasets, omdat de trainingstijd met SVMs hoog kan zijn
- Minder effectief op ruisarmere datasets met overlappende klassen
SVM toepassingen
SVM wordt gebruikt voor tekstclassificatietaken, zoals categorietoewijzing, het detecteren van spam en sentimentanalyse. Het wordt ook vaak gebruikt voor beeldherkenningstaken, waarbij het bijzonder goed presteert in aspect-gebaseerde herkenning en kleur-gebaseerde classificatie. SVM speelt ook een vitale rol in veel gebieden van handgeschreven cijferherkenning, zoals postautomatiseringsdiensten.
Hier heb je het, een introductie op zeer hoog niveau van Support Vector Machines. Als u dieper in SVM wilt duiken, raden wij u aan een link naar een video of een meer diepgaande blog te bekijken (te vinden).
Over: Deze blog is oorspronkelijk gepubliceerd op de AYLIEN Text Analysis blog. AYLIEN biedt tools en diensten om ontwikkelaars en datawetenschappers te helpen om ongestructureerde inhoud op schaal te begrijpen.
Origineel. Herplaatst met toestemming.
Gerelateerd:
- Hoe selecteer je Support Vector Machine Kernels
- Wanneer werkt Deep Learning beter dan SVMs of Random Forests?
- Machine Learning Key Terms, Uitgelegd