Na investigação que investiga uma potencial relação de causa e efeito, uma variável confounding é uma terceira variável não medida que influencia tanto a suposta causa como o suposto efeito.
É importante considerar potenciais variáveis confusas e contabilizá-las no seu projecto de investigação para assegurar que os seus resultados são válidos.
O que é uma variável confusa?
As variáveis confusas, que também são chamadas confusas ou factores confusos, estão intimamente relacionadas com as variáveis independentes e dependentes de um estudo. Uma variável deve satisfazer duas condições para ser confundidora:
- Deve estar correlacionada com a variável independente. Esta pode ser uma relação causal, mas não tem de ser.
- Tem de estar relacionada causalmente com a variável dependente.
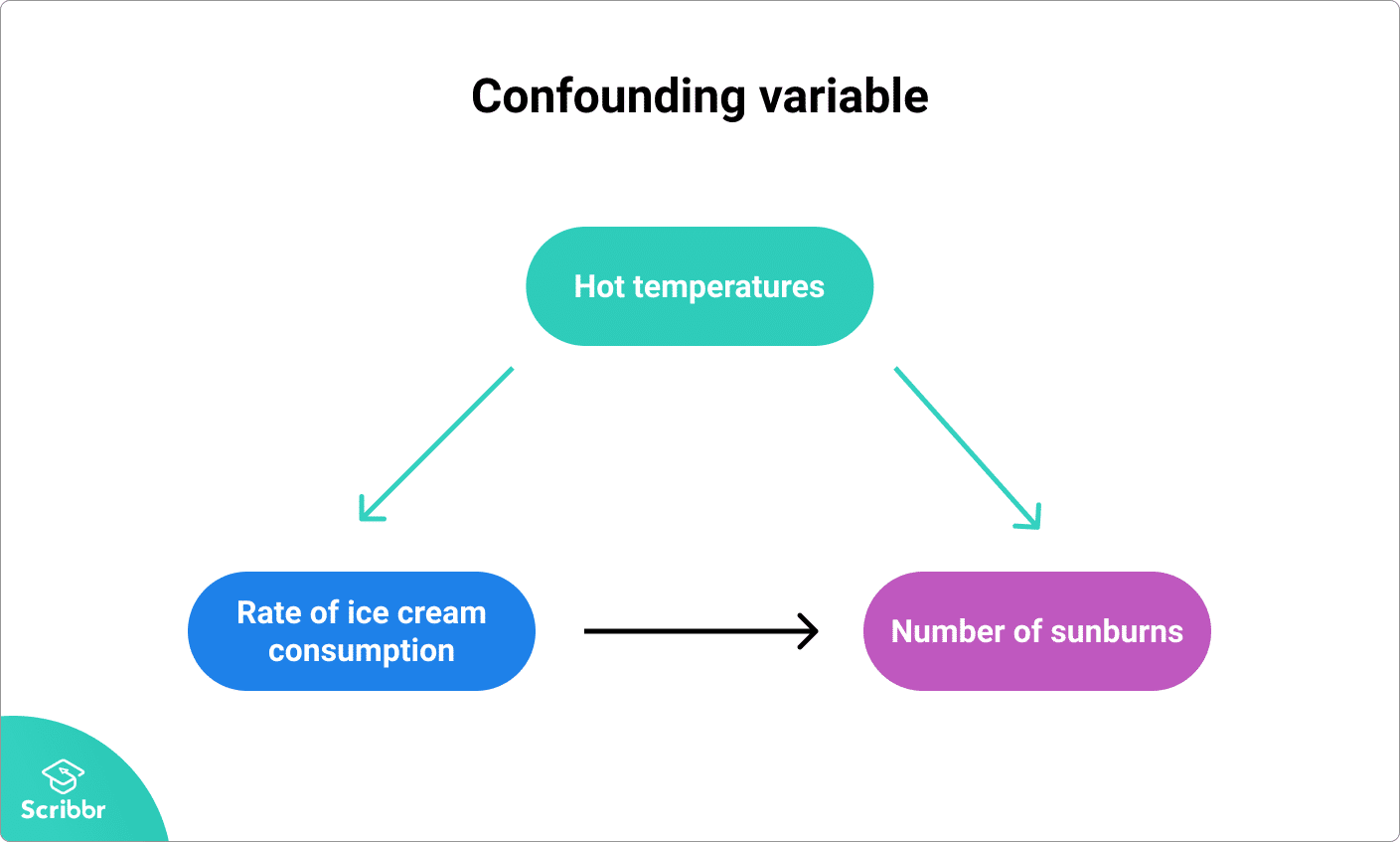
Aqui, a variável de confusão é a temperatura: as temperaturas quentes fazem com que as pessoas comam mais gelado e passem mais tempo ao ar livre sob o sol, resultando em mais queimaduras solares.
Por que razão as variáveis de confusão são importantes
Para assegurar a validade interna da sua investigação, deve ter em conta as variáveis que confundem. Se não o fizer, os seus resultados podem não reflectir a relação real entre as variáveis em que está interessado..
Por exemplo, pode encontrar uma relação de causa e efeito que não existe realmente, porque o efeito que mede é causado pela variável confusa (e não pela sua variável independente).
Não necessariamente. Talvez os estados com melhores mercados de trabalho sejam mais propensos a aumentar os seus salários mínimos, em vez do contrário. Deve considerar as tendências de emprego anteriores na sua análise do impacto do salário mínimo no emprego, ou poderá encontrar uma relação causal onde não existe nenhuma.
p>Even se identificar correctamente uma relação causa-e-efeito, variáveis confusas podem resultar em sobre- ou subestimar o impacto da sua variável independente na sua variável dependente.

Como reduzir o impacto de variáveis de confusão
Existem vários métodos de contabilização de variáveis de confusão. Pode utilizar os seguintes métodos ao estudar qualquer tipo de disciplinas – humanos, animais, plantas, produtos químicos, etc. Cada método tem as suas próprias vantagens e desvantagens.
Restrição
Neste método, restringe o seu grupo de tratamento incluindo apenas sujeitos com os mesmos valores de potenciais factores de confusão.
P>Desde que estes valores não diferem entre os sujeitos do seu estudo, não podem correlacionar-se com a sua variável independente e, portanto, não podem confundir a relação de causa e efeito que está a estudar.
ul>
Casamento
Neste método, selecciona um grupo de comparação que coincida com o grupo de tratamento. Cada membro do grupo de comparação deve ter uma contraparte no grupo de tratamento com os mesmos valores de potenciais confundidores, mas valores de variáveis independentes diferentes.
Isto permite eliminar a possibilidade de que as diferenças nas variáveis confundidoras causem a variação nos resultados entre o grupo de tratamento e o grupo de comparação. Se tiver contabilizado quaisquer potenciais confundidores, pode assim concluir que a diferença na variável independente deve ser a causa da variação na variável dependente.
Cada disciplina de uma dieta pobre em hidratos de carbono é equiparada a outra disciplina com as mesmas características e que não esteja a fazer dieta. Assim, para cada homem de 40 anos de idade com um nível de instrução elevado que segue uma dieta pobre em hidratos de carbono, encontra outro homem de 40 anos com um nível de instrução elevado que não o faz, para comparar a perda de peso entre as duas disciplinas. Faz o mesmo para todos os outros sujeitos da sua amostra de tratamento.
ul>
Controlo estatístico
Se já tiver recolhido os dados, pode incluir os possíveis confundidores como variáveis de controlo nos seus modelos de regressão; desta forma, controlará o impacto da variável de confusão.
Um efeito que a variável potencialmente confusa tenha sobre a variável dependente aparecerá nos resultados da regressão e permitir-lhe-á separar o impacto da variável independente.
ul>
Randomização
Outra forma de minimizar o impacto de variáveis confusas é randomizar os valores da sua variável independente. Por exemplo, se alguns dos seus participantes forem atribuídos a um grupo de tratamento enquanto outros se encontram num grupo de controlo, pode atribuir aleatoriamente participantes a cada grupo.
A aleatorização assegura que, com uma amostra suficientemente grande, todas as potenciais variáveis de confusão – mesmo aquelas que não pode observar directamente no seu estudo – terão o mesmo valor médio entre diferentes grupos. Uma vez que estas variáveis não diferem por atribuição de grupo, não podem correlacionar-se com a sua variável independente e, portanto, não podem confundir o seu estudo.
Posto que este método lhe permite contabilizar todas as variáveis potencialmente confusas, o que é quase impossível de fazer de outra forma, é frequentemente considerado como a melhor forma de reduzir o impacto das variáveis confusas.
A aleatorização garante que tanto o seu tratamento (o grupo pobre em hidratos de carbono) como o seu grupo de controlo terão não só a mesma média de idade, educação e níveis de exercício, mas também os mesmos valores médios sobre outras características que não tenha medido tão bem.
- Permite-lhe ter em conta todas as variáveis de confusão possíveis, incluindo aquelas que não pode observar directamente
- Considerou o melhor método para minimizar o impacto das variáveis de confusão
- Mais difícil de realizar
- Deve ser implementado antes de se iniciarem os dados recolha
- Você deve assegurar-se de que apenas aqueles no grupo de tratamento (e não de controlo) recebem o tratamento
Perguntas frequentes sobre variáveis confusas
Uma variável de confusão, também chamada de confundidor ou factor de confusão, é uma terceira variável num estudo que examina uma potencial relação de causa e efeito.
Uma variável de confusão está relacionada tanto com a suposta causa como com o suposto efeito do estudo. Pode ser difícil separar o verdadeiro efeito da variável independente do efeito da variável confusa.
Na sua concepção da investigação, é importante identificar potenciais variáveis confusas e planear como irá reduzir o seu impacto.
Uma variável de confusão está intimamente relacionada tanto com as variáveis independentes como com as variáveis dependentes num estudo. Uma variável independente representa a suposta causa, enquanto que a variável dependente é o suposto efeito. Uma variável confusa é uma terceira variável que influencia tanto as variáveis independentes como as dependentes.
Falecer de prestar contas pelas variáveis confusas pode fazer com que se estime erradamente a relação entre as variáveis independentes e dependentes.
Para assegurar a validade interna da sua investigação, deve considerar o impacto das variáveis confusas. Se não as contabilizar, poderá sobrestimar ou subestimar a relação causal entre as suas variáveis independentes e dependentes, ou mesmo encontrar uma relação causal onde nenhuma existe.
Existem vários métodos que pode utilizar para diminuir o impacto das variáveis de confusão na sua investigação: restrição, correspondência, controlo estatístico e randomização.
Em restrição, restringe a sua amostra incluindo apenas certos sujeitos que têm os mesmos valores de potenciais variáveis de confusão.
Em correspondência, compara cada um dos sujeitos do seu grupo de tratamento com um homólogo no grupo de comparação. Os sujeitos combinados têm os mesmos valores em quaisquer potenciais variáveis de confusão, e diferem apenas na variável independente.
No controlo estatístico, inclui potenciais confundidores como variáveis na sua regressão.
Na aleatorização, atribui aleatoriamente o tratamento (ou variável independente) no seu estudo a um número suficientemente grande de sujeitos, o que lhe permite controlar para todas as potenciais variáveis de confusão.