Por Noel Bambrick, AYLIEN.
Introdução
Neste post, vamos apresentar-lhe o algoritmo de aprendizagem de máquinas Vector de Apoio (SVM). Vamos seguir um processo semelhante ao nosso recente post Naive Bayes for Dummies; Uma explicação simples, mantendo-o curto e não excessivamente técnico. O objectivo é dar àqueles que são novos na aprendizagem de máquinas uma compreensão básica dos conceitos-chave deste algoritmo.
Support Vector Machines – What are they?
A Support Vector Machine (SVM) é um algoritmo de aprendizagem de máquinas supervisionado que pode ser utilizado tanto para fins de classificação como de regressão. As SVMs são mais comummente utilizadas em problemas de classificação e, como tal, é nisto que nos vamos concentrar neste post.
SVMs baseiam-se na ideia de encontrar um hiperplano que melhor divida um conjunto de dados em duas classes, como se mostra na imagem abaixo.
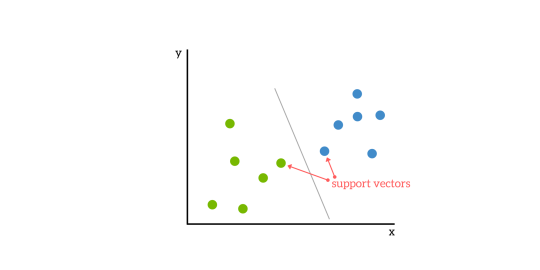
Vectores de suporte
Vectores de suporte são os pontos de dados mais próximos do hiperplano, os pontos de um conjunto de dados que, se removidos, alterariam a posição do hiperplano divisor. Devido a isto, podem ser considerados os elementos críticos de um conjunto de dados.
O que é um hiperplano?
Como exemplo simples, para uma tarefa de classificação com apenas duas características (como a imagem acima), pode-se pensar num hiperplano como uma linha que separa e classifica linearmente um conjunto de dados.
Intuitivamente, quanto mais longe do hiperplano estiverem os nossos pontos de dados, mais confiantes estamos de que foram classificados correctamente. Por conseguinte, queremos que os nossos pontos de dados estejam o mais afastados possível do hiperplano, enquanto ainda estiverem no lado correcto do mesmo.
Então, quando novos dados de teste forem adicionados, qualquer lado do hiperplano que aterrar decidirá a classe que lhe atribuímos.
Como é que encontramos o hiperplano certo?
Or, por outras palavras, como é que separamos melhor as duas classes dentro dos dados?
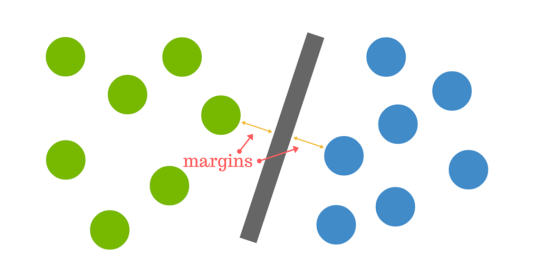
A distância entre o hiperplano e o ponto de dados mais próximo de qualquer um dos conjuntos é conhecida como margem. O objectivo é escolher um hiperplano com a maior margem possível entre o hiperplano e qualquer ponto dentro do conjunto de treino, dando uma maior probabilidade de novos dados serem classificados correctamente.
Mas o que acontece quando não há um hiperplano claro?
É aqui que se pode complicar. Os dados raramente são tão limpos como o nosso simples exemplo acima. Um conjunto de dados será muitas vezes mais parecido com as bolas emaranhadas abaixo das quais representam um conjunto de dados linearmente não separável.
 here.
here.
p>Porque agora estamos em três dimensões, o nosso hiperplano já não pode ser uma linha. Deve agora ser um avião, como se mostra no exemplo acima. A ideia é que os dados continuarão a ser mapeados em dimensões cada vez mais elevadas até que um hiperplano possa ser formado para o segregar.
Pros & Cons of Support Vector Machines
Pros
- Accuracy
- Trabalha bem em conjuntos de dados mais pequenos de limpeza
- Pode ser mais eficiente porque utiliza um subconjunto de pontos de treino
Cons
- Não é adequado para conjuntos de dados maiores, pois o tempo de formação com SVMs pode ser elevado
- Li>Menos eficaz em conjuntos de dados mais ruidosos com classes sobrepostas
Usos SVM
SVM é utilizado para tarefas de classificação de texto, tais como atribuição de categorias, detecção de spam e análise de sentimentos. É também comummente utilizado para desafios de reconhecimento de imagem, tendo um desempenho particularmente bom no reconhecimento baseado em pontos e classificação baseada em cores. SVM desempenha também um papel vital em muitas áreas de reconhecimento de dígitos manuscritos, tais como serviços de automação postal.
Existe uma introdução de alto nível ao Support Vector Machines. Se quiser mergulhar mais fundo na SVM, recomendamos que faça um check-out (necessidade de encontrar um link para um vídeo ou um blog mais aprofundado).
About: Este blog foi originalmente publicado no blog AYLIEN Text Analysis. AYLIEN fornece ferramentas e serviços para ajudar os programadores e cientistas de dados a fazer sentido de conteúdo não estruturado em escala.
Original. Reportado com permissão.
Related:
- Como Seleccionar os Núcleos de Máquinas Vectoriais de Apoio
- Quando o Aprendizagem Profunda Funciona Melhor que as SVMs ou Florestas Aleatórias?
- Termos Chave de Aprendizagem da Máquina, Explicados