Von Noel Bambrick, AYLIEN.
Einführung
In diesem Beitrag werden wir Ihnen den Support Vector Machine (SVM) Machine Learning Algorithmus vorstellen. Wir werden dabei ähnlich vorgehen wie in unserem kürzlich erschienenen Beitrag Naive Bayes für Dummies; Eine einfache Erklärung, indem wir ihn kurz und nicht allzu technisch halten. Ziel ist es, denjenigen unter Ihnen, die neu im Bereich des maschinellen Lernens sind, ein grundlegendes Verständnis der Schlüsselkonzepte dieses Algorithmus zu vermitteln.
Support Vector Machines – Was sind sie?
Eine Support Vector Machine (SVM) ist ein überwachter maschineller Lernalgorithmus, der sowohl für Klassifizierungs- als auch für Regressionszwecke eingesetzt werden kann. SVMs werden häufiger bei Klassifizierungsproblemen eingesetzt, weshalb wir uns in diesem Beitrag darauf konzentrieren werden.
SVMs basieren auf der Idee, eine Hyperebene zu finden, die einen Datensatz am besten in zwei Klassen unterteilt, wie in der folgenden Abbildung dargestellt.
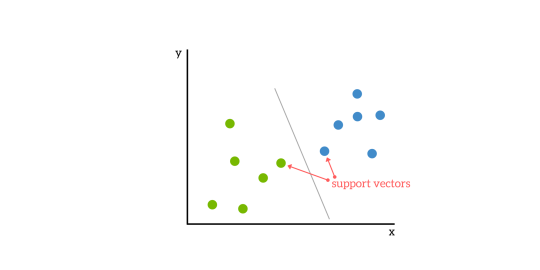
Unterstützungsvektoren
Unterstützungsvektoren sind die Datenpunkte, die der Hyperebene am nächsten liegen, also die Punkte eines Datensatzes, die, wenn sie entfernt würden, die Position der teilenden Hyperebene verändern würden. Aus diesem Grund können sie als die kritischen Elemente eines Datensatzes betrachtet werden.
Was ist eine Hyperebene?
Als einfaches Beispiel für eine Klassifizierungsaufgabe mit nur zwei Merkmalen (wie das Bild oben) können Sie sich eine Hyperebene als eine Linie vorstellen, die einen Datensatz linear trennt und klassifiziert.
Intuitiv gilt: Je weiter unsere Datenpunkte von der Hyperebene entfernt liegen, desto sicherer sind wir, dass sie richtig klassifiziert wurden. Wir wollen also, dass unsere Datenpunkte so weit wie möglich von der Hyperebene entfernt sind, aber trotzdem auf der richtigen Seite liegen.
Wenn also neue Testdaten hinzugefügt werden, entscheidet die Seite der Hyperebene, auf der sie landen, über die Klasse, die wir ihnen zuordnen.
Wie findet man die richtige Hyperebene?
Oder, in anderen Worten, wie trennt man die beiden Klassen innerhalb der Daten am besten?
Der Abstand zwischen der Hyperebene und dem nächstgelegenen Datenpunkt aus einem der beiden Sätze wird als Rand bezeichnet. Das Ziel ist es, eine Hyperebene mit dem größtmöglichen Abstand zwischen der Hyperebene und einem beliebigen Punkt innerhalb des Trainingssatzes zu wählen, was eine größere Chance bietet, dass neue Daten richtig klassifiziert werden.
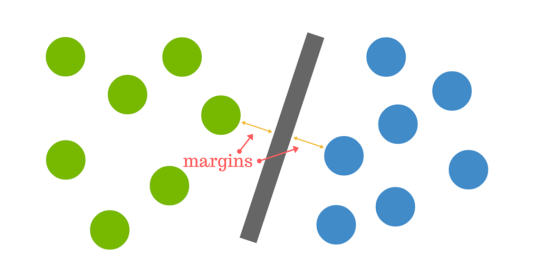
Aber was passiert, wenn es keine eindeutige Hyperebene gibt?
Hier kann es knifflig werden. Daten sind selten so sauber wie in unserem einfachen Beispiel oben. Ein Datensatz wird oft eher wie die durcheinandergewürfelten Kugeln unten aussehen, die einen linear nicht trennbaren Datensatz darstellen.
 hier.
hier.
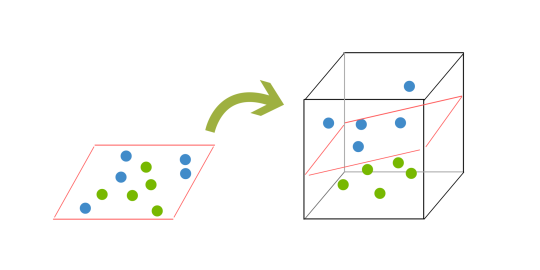
Da wir uns nun in drei Dimensionen befinden, kann unsere Hyperebene nicht länger eine Linie sein. Sie muss jetzt eine Ebene sein, wie im obigen Beispiel gezeigt. Die Idee ist, dass die Daten immer weiter in immer höhere Dimensionen abgebildet werden, bis eine Hyperebene gebildet werden kann, die die Daten trennt.
Pros & Nachteile von Support Vector Machines
Pros
- Genauigkeit
- Arbeitet gut auf kleineren, sauberen Datensätzen
- Es kann effizienter sein, da es eine Teilmenge von Trainingspunkten verwendet
Nachteile
- Ist nicht für größere Datensätze geeignet, da die Trainingszeit mit SVMs hoch sein kann
- Nicht so effektiv bei verrauschten Datensätzen mit überlappenden Klassen
SVM-Verwendung
SVM wird für Textklassifizierungsaufgaben verwendet, wie z. B. Kategoriezuordnung, Spam-Erkennung und Sentiment-Analyse. Sie wird auch häufig für Bilderkennungsaufgaben verwendet, wobei sie besonders gut bei aspektbasierter Erkennung und farbbasierter Klassifikation abschneidet. SVM spielt auch eine wichtige Rolle in vielen Bereichen der Erkennung handgeschriebener Ziffern, wie z.B. bei der Postautomatisierung.
Das war eine sehr allgemeine Einführung in Support Vector Machines. Wenn Sie tiefer in die SVM eintauchen möchten, empfehlen wir Ihnen, einen Link zu einem Video oder einem tiefer gehenden Blog zu finden.
About: Dieser Blog wurde ursprünglich auf dem AYLIEN Text Analysis Blog veröffentlicht. AYLIEN bietet Tools und Services, die Entwicklern und Datenwissenschaftlern helfen, unstrukturierte Inhalte in großem Umfang sinnvoll zu nutzen.
Original. Reposted with permission.
Related:
- How to Select Support Vector Machine Kernels
- Wann funktioniert Deep Learning besser als SVMs oder Random Forests?
- Machine Learning Key Terms, Explained