Statistik Definitionen >
Was ist die Likert-Skala?
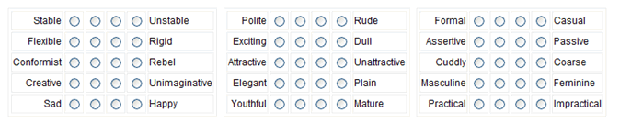
Varianten der Likert-Skala.
Eine Likert-Skala ist eine Art von Bewertungsskala, die zur Messung von Einstellungen oder Meinungen verwendet wird. Bei dieser Skala werden die Befragten gebeten, Items auf einem Zustimmungsniveau zu bewerten. Zum Beispiel:
- Stimmt voll und ganz zu
- Stimmt zu
- Neutral
- Stimmt nicht zu
- Stimmt überhaupt nicht zu
In der Skala werden normalerweise fünf bis sieben Items verwendet. Die Skala muss nicht „stimme zu“ oder „stimme nicht zu“ angeben; es sind Dutzende von Variationen zu Themen wie Zustimmung, Häufigkeit, Qualität und Wichtigkeit möglich. Zum Beispiel:
- Zustimmung: Starke Zustimmung bis starke Ablehnung.
- Häufigkeit: Oft bis nie.
- Qualität: Sehr gut bis sehr schlecht.
- Wahrscheinlichkeit: Definitiv bis nie.
- Wichtigkeit: Sehr wichtig bis unwichtig.
Diese Items werden als Antwortanker der Likert-Skala bezeichnet.
Nachdem die Befragten geantwortet haben, werden den Antworten Zahlen zugeordnet. Zum Beispiel:
Stimmt voll und ganz zu=5
Stimmt zu=4
Neutral=3
Stimmt nicht zu=2
Stimmt überhaupt nicht zu=1
So können Sie den Antworten eine Bedeutung zuordnen. So können Sie z.B. bei einer Umfrage zum Kundenservice erkennen, welche Ihrer Kundendienstmitarbeiter einen guten Service bieten (Durchschnittswert von 4-5) und welche einen schlechten Service bieten (Durchschnittswert von 1-2).
Schritte zur Entwicklung einer Likert-Skala
- Legen Sie den Fokus fest: Was ist es, das Sie zu messen versuchen? Ihr Thema sollte eindimensional sein. Zum Beispiel „Kundenservice“ oder „Diese Website.“
- Erstellen Sie die Items der Likert-Skala. Die Items sollten auf einer Art von Skala bewertet werden können. Das Bild oben auf dieser Seite enthält einige Vorschläge. Zum Beispiel könnte Höflichkeit/Unhöflichkeit als „sehr höflich“, „höflich“, „nicht höflich“ oder „sehr unhöflich“ bewertet werden. Höflichkeit könnte auch auf einer Skala von 1 bis 10 bewertet werden, wobei 1 überhaupt nicht höflich und 10 extrem höflich ist.
- Bewerten Sie die Items der Likert-Skala. Sie wollen sicher sein, dass Ihr Fokus gut ist, also wählen Sie ein Team von Leuten aus, die die Punkte in Schritt 2 oben durchgehen und sie als günstig/neutral/ungünstig für Ihren Fokus bewerten. Sortieren Sie die Items aus, die am häufigsten als ungünstig angesehen werden.
- Führen Sie Ihren Likert-Skala-Test durch.
Hypothesentests auf Likert-Skalen
Wenn Sie wissen, dass Sie eine Analyse auf Likert-Skala-Daten durchführen werden, ist es einfacher, Ihre Fragen in der Entwicklungsphase anzupassen, als Ihre Daten zu sammeln und dann eine Entscheidung über die Analyse zu treffen. Welche Analyse Sie durchführen, hängt vom Format Ihres Fragebogens ab.
In der Lehre und Forschung herrscht Uneinigkeit darüber, ob Sie parametrische Tests wie den t-Test oder nicht-parametrische Hypothesentests wie den Mann-Whitney-Test auf Likert-Skala-Daten durchführen sollten. Winter und Dodou(2010) untersuchten diese Frage mit folgenden Ergebnissen:
„Zusammenfassend lässt sich sagen, dass der t-Test und im Allgemeinen eine äquivalente Aussagekraft haben, mit Ausnahme von schiefen, spitzen oder multimodalen Verteilungen, für die starke Unterschiede in der Aussagekraft zwischen den beiden Tests auftreten. Die Typ-I-Fehlerrate beider Methoden lag nie mehr als 3 % über der nominalen Rate von 5 %, selbst dann nicht, wenn die Stichprobengrößen sehr ungleich waren.“
Mit anderen Worten, es scheint keinen wirklichen Unterschied zwischen den Ergebnissen für parametrische und nicht-parametrische Tests zu geben, außer für schiefe, spitze oder multimodale Verteilungen. Welchen Weg Sie einschlagen, hängt von Ihnen, Ihrer Abteilung und vielleicht der Zeitschrift ab, bei der Sie einreichen (falls vorhanden). Der wichtigste Schritt in der Entscheidungsphase ist die Entscheidung, ob Sie Ihre Daten als Ordinal- oder Intervalldaten behandeln wollen. Lesen Sie dann den Abschnitt unten für Ihren Datentyp. Ein paar allgemeine Richtlinien:
- Bei einer Reihe von Einzelfragen mit Likert-Antworten behandeln Sie die Daten als Ordinalvariablen.
- Bei einer Reihe von Likert-Fragen, die zusammen ein einzelnes Konstrukt beschreiben (Persönlichkeitsmerkmal oder Einstellung), behandeln Sie die Daten als Intervallvariablen.
Zwei Optionen
Die meisten Likert-Skalen werden als Ordinalvariablen klassifiziert. Wenn Sie sich zu 100 % sicher sind, dass der Abstand zwischen den Variablen konstant ist, dann können sie zu Testzwecken als Intervallvariablen behandelt werden. In den meisten Fällen werden Ihre Daten ordinal sein, da es unmöglich ist, den Unterschied zwischen, sagen wir, „stimme voll zu“ und „stimme zu“ vs. „stimme zu“ und „neutral“
Ordinalskalendaten
Bei den meisten Variablentypen (Intervall, Verhältnis, nominal) können Sie den Mittelwert finden. Dies gilt nicht für Likert-Skala-Daten. Der Mittelwert in einer Likert-Skala kann nicht gefunden werden, weil Sie den „Abstand“ zwischen den Datenelementen nicht kennen. Mit anderen Worten: Sie können zwar einen Mittelwert von 1, 2 und 3 finden, aber keinen Mittelwert von „stimme zu“, „stimme nicht zu“ und „neutral“.
„Der Durchschnitt von ‚fair‘ und ‚gut‘ ist nicht ‚fair-and-a-half‘; was auch dann gilt, wenn man ganze Zahlen zur Darstellung von ‚fair‘ und ‚gut‘ einsetzt!“ – Susan Jamieson paraphrasiert Kuzon Jr. et al. (Jamieson, 2004)
Statistische Auswahlmöglichkeiten
Statistiken, die Sie verwenden können, sind:
- Der Modus: die häufigste Antwort.
- Der Median: die „mittlere“ Antwort, wenn alle Items in eine Reihenfolge gebracht werden.
- Der Bereich und der Interquartilsbereich: um die Variabilität zu zeigen.
- Ein Balkendiagramm oder eine Häufigkeitstabelle: um eine Tabelle der Ergebnisse zu zeigen. Erstellen Sie kein Histogramm, da die Daten nicht kontinuierlich sind.
Hypothesentest
Beim Hypothesentest für Likert-Skalen stellt die unabhängige Variable die Gruppen und die abhängige Variable das Konstrukt dar, das Sie messen. Wenn Sie z. B. Krankenpflegeschüler befragen, um ihr Maß an Mitgefühl zu messen, ist die unabhängige Variable die Gruppe der Krankenpflegeschüler und die abhängige Variable ist das Maß an Mitgefühl.
Typen von Tests, die Sie durchführen können:
- Kruskal Wallis: bestimmt, ob der Median für zwei Gruppen unterschiedlich ist.
- Mann Whitney U Test: bestimmt, ob die Mediane für zwei Gruppen unterschiedlich sind. Einfach, um einzelne Fragen der Likert-Skala auszuwerten, leidet aber unter verschiedenen Formen von Verzerrungen, einschließlich der Verzerrung der zentralen Tendenz, der Akzeptanzverzerrung und der Verzerrung der sozialen Erwünschtheit. Außerdem ist die Validität in der Regel schwer nachzuweisen.
Mehr Optionen für zwei Kategorien
Wenn Sie Ihre Antworten in zwei Kategorien zusammenfassen, z. B. zustimmen und nicht zustimmen, eröffnen sich Ihnen mehr Testmöglichkeiten.
- Chi-Quadrat: Der Test ist für multinomiale Experimente ausgelegt, bei denen die Ergebnisse in Kategorien eingeteilt werden.
- McNemar-Test: Testet, ob die Antworten auf Kategorien für zwei Gruppen/Bedingungen gleich sind.
- Cochran’s Q-Test: Eine Erweiterung von McNemar, die testet, ob die Antworten auf Kategorien für drei oder mehr Gruppen/Bedingungen gleich sind.
- Friedman-Test: zum Auffinden von Unterschieden in Behandlungen über mehrere Versuche.
Assoziationsmaße
Manchmal möchte man wissen, ob eine Gruppe von Personen eine andere Antwort (höher oder niedriger) als eine andere Gruppe von Personen auf ein bestimmtes Item der Likert-Skala hat. Um diese Frage zu beantworten, würden Sie ein Assoziationsmaß anstelle eines Tests auf Unterschiede (wie die oben aufgeführten) verwenden.
Wenn Ihre Gruppen in irgendeiner Weise ordinal (d.h. geordnet) sind, wie z.B. Altersgruppen, können Sie verwenden:
- Kendall’s Tau-Koeffizient oder Varianten von Tau (z.B. Gamma-Koeffizient; Somers‘ D).
- Spearman-Rangkorrelation.
Wenn Ihre Gruppen nicht ordinal sind, dann verwenden Sie eine der folgenden Möglichkeiten:
- Phi-Koeffizient.
- Kontingenzkoeffizient.
- Cramer’s V.
Intervallskala-Daten
Statistiken, die für Intervallskala-Likert-Daten geeignet sind:
- Mittelwert.
- Standardabweichung.
Hypothesentests, die für Intervallskala-Likert-Daten geeignet sind:
- T-Test.
- ANOVA.
- Regressionsanalyse (entweder geordnete logistische Regression oder multinomiale logistische Regression). Wenn Sie Ihre abhängigen Variablen in zwei Antworten kombinieren können (z.B. stimme zu oder stimme nicht zu), führen Sie eine binäre logistische Regression durch.
——————————————————————————
Brauchen Sie Hilfe bei einer Hausaufgabe oder Testfrage? Mit Chegg Study können Sie Schritt-für-Schritt-Lösungen zu Ihren Fragen von einem Experten auf dem Gebiet erhalten. Ihre ersten 30 Minuten mit einem Chegg Tutor sind kostenlos!