Di Noel Bambrick, AYLIEN.
Introduzione
In questo post, vi presenteremo l’algoritmo di apprendimento automatico Support Vector Machine (SVM). Seguiremo un processo simile al nostro recente post Naive Bayes for Dummies; A Simple Explanation, mantenendolo breve e non eccessivamente tecnico. Lo scopo è quello di dare a quelli di voi che sono nuovi all’apprendimento automatico una comprensione di base dei concetti chiave di questo algoritmo.
Support Vector Machines – Cosa sono?
Una Support Vector Machine (SVM) è un algoritmo di apprendimento automatico supervisionato che può essere impiegato sia per la classificazione che per la regressione. Le SVM sono più comunemente usate nei problemi di classificazione e come tali, questo è ciò su cui ci concentreremo in questo post.
Le SVM sono basate sull’idea di trovare un iperpiano che divida al meglio un set di dati in due classi, come mostrato nell’immagine qui sotto.
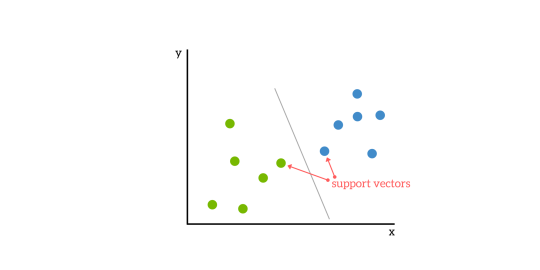
Vettori di supporto
I vettori di supporto sono i punti dati più vicini all’iperpiano, i punti di un set di dati che, se rimossi, altererebbero la posizione dell’iperpiano di divisione. Per questo motivo, possono essere considerati gli elementi critici di un insieme di dati.
Cos’è un iperpiano?
Come semplice esempio, per un compito di classificazione con solo due caratteristiche (come l’immagine sopra), si può pensare a un iperpiano come a una linea che separa linearmente e classifica un insieme di dati.
Intuitivamente, più lontano dall’iperpiano si trovano i nostri punti dati, più siamo sicuri che siano stati classificati correttamente. Vogliamo quindi che i nostri punti dati siano il più lontano possibile dall’iperpiano, pur rimanendo sul lato corretto di esso.
Quindi, quando vengono aggiunti nuovi dati di test, qualunque sia il lato dell’iperpiano su cui atterrano deciderà la classe che gli assegneremo.
Come facciamo a trovare l’iperpiano giusto?
Ovvero, in altre parole, come facciamo a separare al meglio le due classi all’interno dei dati?
La distanza tra l’iperpiano e il punto dati più vicino di entrambi i set è nota come margine. L’obiettivo è quello di scegliere un iperpiano con il maggior margine possibile tra l’iperpiano e qualsiasi punto all’interno dell’insieme di allenamento, dando una maggiore possibilità che i nuovi dati siano classificati correttamente.
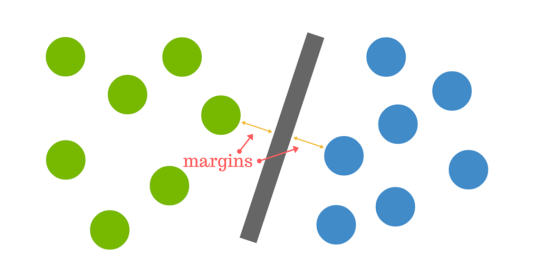
Ma cosa succede quando non c’è un iperpiano chiaro?
È qui che può diventare difficile. I dati raramente sono così puliti come il nostro semplice esempio sopra. Un set di dati spesso assomiglia alle palline mescolate qui sotto che rappresentano un set di dati linearmente non separabili.
 qui.
qui.
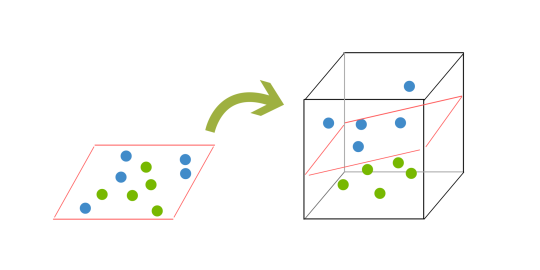
Perché ora siamo in tre dimensioni, il nostro iperpiano non può più essere una linea. Ora deve essere un piano come mostrato nell’esempio sopra. L’idea è che i dati continueranno ad essere mappati in dimensioni sempre più alte fino a quando si potrà formare un iperpiano per segregarli.
Pro & Contro delle macchine vettoriali di supporto
Pro
- Precisione
- Funziona bene su set di dati più piccoli e puliti
- Può essere più efficiente perché usa un sottoinsieme di punti di allenamento
Cons
- Non è adatto ad insiemi di dati più grandi perché il tempo di addestramento con SVM può essere elevato
- Meno efficace su insiemi di dati più rumorosi con classi sovrapposte
Usi di SVM
SVM è usato per compiti di classificazione del testo come l’assegnazione di categorie, l’individuazione dello spam e l’analisi del sentimento. È anche comunemente usato per le sfide di riconoscimento delle immagini, con prestazioni particolarmente buone nel riconoscimento basato sugli aspetti e nella classificazione basata sul colore. SVM gioca anche un ruolo vitale in molte aree di riconoscimento delle cifre scritte a mano, come i servizi di automazione postale.
Eccovi un’introduzione di alto livello alle Support Vector Machines. Se volete immergervi più a fondo in SVM vi consigliamo di controllare (bisogna trovare un link a un video o a un blog più approfondito).
A proposito: Questo blog è stato originariamente pubblicato sul blog AYLIEN Text Analysis. AYLIEN fornisce strumenti e servizi per aiutare gli sviluppatori e gli scienziati di dati a dare un senso ai contenuti non strutturati su scala.
Originale. Reposted with permission.
Related:
- Come selezionare i kernel delle Support Vector Machine
- Quando il Deep Learning funziona meglio di SVM o Random Forests?
- Termini chiave dell’apprendimento automatico, spiegati