By Noel Bambrick, AYLIEN.
Introduction
この記事では、サポート ベクトル マシン (SVM) 機械学習アルゴリズムをご紹介します。 最近投稿した「Naive Bayes for Dummies; A Simple Explanation」と同様のプロセスで、過度に専門的ではなく、簡潔に説明します。
サポート ベクトル マシン – とは?
サポート ベクトルマシン (SVM)は、分類と回帰の両方に使用できる教師付き機械学習アルゴリズムです。
SVM は、下の図のように、データセットを 2 つのクラスに分けるのに最適な超平面を見つけるというアイデアに基づいています。
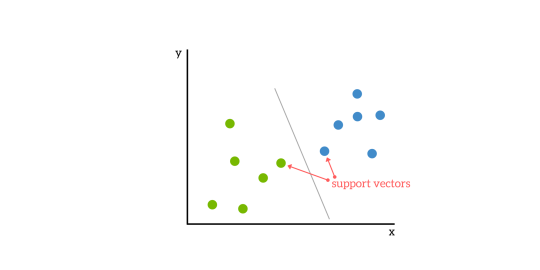
サポートベクター
サポートベクターとは、超平面に最も近いデータポイントのことで、削除すると分割超平面の位置が変わってしまうようなデータセットのポイントのことです。
超平面とは
簡単な例として、(上の画像のような)2つの特徴しかない分類タスクの場合、超平面はデータセットを直線的に分離して分類する線と考えることができます。
直感的には、データポイントが超平面から遠くなるほど、正しく分類されたという確信が持てます。
直感的には、データ ポイントが超平面から離れていればいるほど、そのデータが正しく分類されたことを確信できます。したがって、データ ポイントが超平面からできる限り離れていて、なおかつ超平面の正しい側にあることが望まれます。
どうやって正しい超平面を見つけるか
つまり、どのようにしてデータ内の 2 つのクラスを最適に分離するかということです。
超平面と、どちらかのセットから最も近いデータ ポイントとの間の距離は、マージンとして知られています。
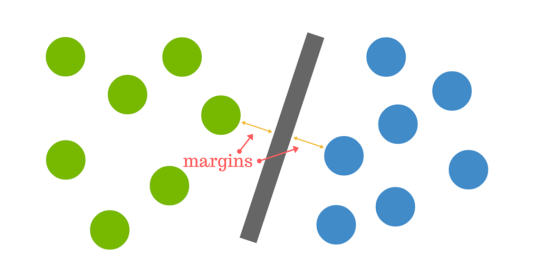
しかし、明確な超平面がない場合はどうなるのでしょうか?
これが厄介なところです。 データは、上記の単純な例のようにきれいなことはほとんどありません。
 はこちら
はこちら
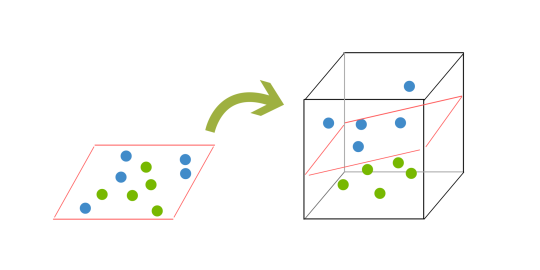
現在は3次元なので、超平面はもはや直線ではありません。 上の例のように、平面である必要があります。 このアイデアは、データを分離するための超平面が形成されるまで、データはより高い次元にマッピングされ続けるということです。
Pros & Cons of Support Vector Machines
Pros
- Accuracy
- より小さいクリーンなデータセットでうまく機能する
- トレーニングポイントのサブセットを使用するので、より効率的である可能性がある
Cons
- Accuracy
- より小さいクリーンなデータセットでうまく機能する。
- SVMの学習時間は長くなるため、大きなデータセットには向いていません
- クラスが重なっているノイズの多いデータセットではあまり効果的ではありません
SVMの用途
SVMは、カテゴリの割り当て、スパムの検出、感情分析などのテキスト分類タスクに使用されます。
SVMは、カテゴリの割り当て、スパムの検出、感情分析などのテキスト分類タスクに使用されます。 また、画像認識の課題にもよく使われており、特にアスペクトベースの認識やカラーベースの分類で優れた性能を発揮します。以上が、サポートベクターマシンの非常に高度な紹介です。
About: このブログはAYLIEN Text Analysisブログに掲載されたものです。 AYLIENは開発者やデータサイエンティストが大規模な非構造化コンテンツを理解するためのツールやサービスを提供しています。
オリジナルです。
Related:
- How to Select Support Vector Machine Kernels
- When Does Deep Learning Work Better Than SVMs or Random Forests?
- Machine Learning Key Terms, Explained