Door: Koen Verbeeck | Bijgewerkt: 2019-05-13 | Reacties (6) | Gerelateerd: Meer > T-SQL

Gratis MSSQLTips Webinar: Development Best Practices for SQL Server
Neem deel aan dit webinar om meer te leren over de best practices voor de ontwikkeling van SQL Server. Andy Warren zal zijn jarenlange ervaring delen om een aantal tips te geven over wat voor hem het beste heeft gewerkt en hoe u iets van deze kennis kunt gebruiken.
Probleem
Is er een verschil tussen het gebruik van de T-SQL IN operator of de EXISTS operator in een WHERE clausule om te filteren op specifieke waarden? Is er een logisch verschil, een verschil in performance of zijn ze precies hetzelfde? En hoe zit het met NOT IN enNOT EXISTS?
Oplossing
In deze tip onderzoeken we of er verschillen zijn tussen deEXISTS en de IN operator. Dit kan zowel logisch zijn, d.w.z. dat ze zich onder bepaalde omstandigheden anders gedragen, als prestatiegericht, d.w.z. of het gebruik van de ene operator een prestatievoordeel heeft ten opzichte van de andere. We gebruiken het AvontuurWorks DW 2017 voor onze test queries.
SQL Server IN vs EXISTS
DeIN operator wordt meestal gebruikt om een kolom te filteren op een bepaalde lijst met waarden.Bijvoorbeeld:
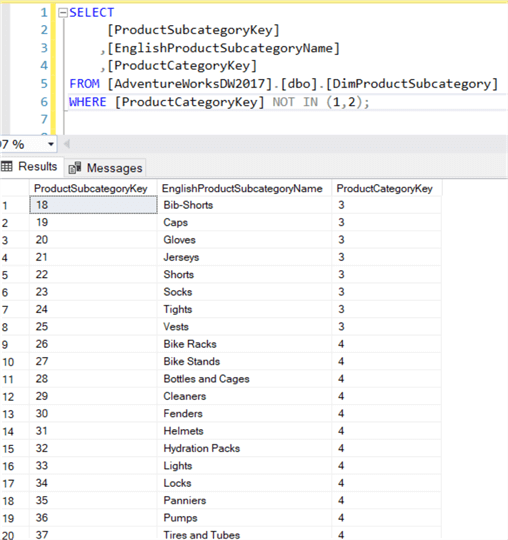
SELECT , ,FROM ..WHERE IN (1,2);
Deze query zoekt naar alle productsubcategorieën die behoren tot de productcategorieën Fietsen en Categorieën (ProductCategoryKey 1 en 2).
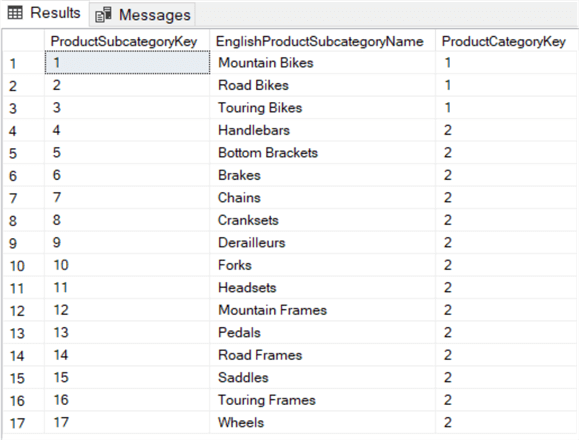
U kunt de IN-operator ook gebruiken om de waarden in de resultatenset van een subquery te doorzoeken:
SELECT , ,FROM ..WHERE IN ( SELECT FROM . WHERE = 'Bikes' );
Deze query geeft alle subcategorieën die zijn gekoppeld aan de categorie Fietsen.
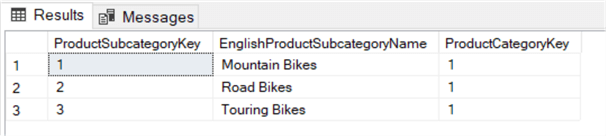
Het voordeel van het gebruik van een subquery is dat de query minder hard gecodeerd is; als de ProductCategoryKey om de een of andere reden verandert, zal de tweede query nog steeds werken, terwijl de eerste query plotseling onjuiste resultaten zou kunnen opleveren. Het is belangrijk dat de subquery precies één kolom retourneert, zodat de IN operator werkt.
DeEXISTS operator controleert niet op waarden, maar in plaats daarvan op het bestaan van rijen. Typisch wordt een subquery gebruikt in combinatie met EXISTS. Het maakt eigenlijk niet uit wat de subquery retourneert, zolang er maar rijen worden geretourneerd.
Deze query retourneert alle rijen uit de tabel ProductSubcategorie, omdat de buitenste subquery rijen retourneert (die helemaal niets met de buitenste query te maken hebben).
SELECT , ,FROM ..WHERE EXISTS ( SELECT 1/0 FROM . WHERE = 'Bikes' );
Zoals je misschien hebt gemerkt, heeft de subquery 1/0 in de SELECT-clausule. In een normale query zou dit een foutmelding opleveren, maar in een EXISTS-clausule is het prima, omdat de deling nooit wordt berekend. Dit laat zien dat het niet belangrijk is wat de subquery retourneert, zolang er maar rijen worden geretourneerd.
Om EXISTS op een meer zinvolle manier te gebruiken, kun je een gecorreleerde subquery gebruiken. In een gecorreleerde subquery koppelen we waarden uit de buitenste query aan waarden uit de binnenste (sub)query. Dit controleert effectief of de waarde van de buitenste query bestaat in de tabel die gebruikt wordt in de binnenste query. Als we bijvoorbeeld een lijst willen terugsturen met alle werknemers die een verkoop hebben gedaan, kunnen we de volgende query schrijven:
SELECT , , ,FROM .. eWHERE EXISTS ( SELECT 1 FROM dbo. f WHERE e. = f. );
In de WHERE-clausule binnen de EXISTS-subquery correleren we de werknemerssleutel van de buitentabel – DimEmployee – met de werknemerssleutel van de binnentabel – FactResellerSales. Als de werknemersleutel bestaat in beide tabellen, wordt een rij teruggegeven en EXISTS zal waar teruggeven. Als de werknemersleutel niet in FactResellerSales wordt gevonden, geeft EXISTS false terug en wordt de werknemer uit de resultaten weggelaten:
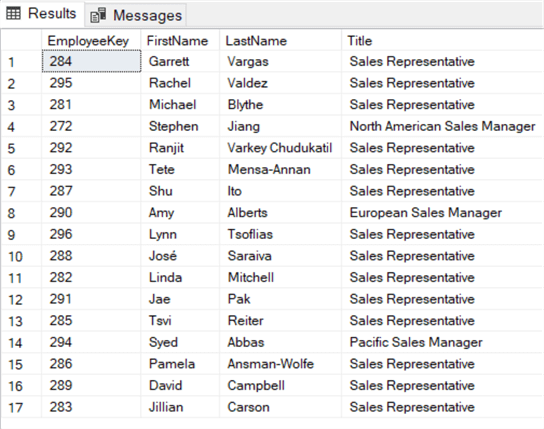
We kunnen dezelfde logica implementeren met behulp van de IN-operator:
SELECT , , ,FROM .. eWHERE IN ( SELECT FROM dbo. f );
Beide query’s leveren dezelfde resultaten op, maar misschien is er een onderliggend verschil in prestaties? Laten we de uitvoeringsplannen eens vergelijken.
Dit is het plan voor EXISTS:
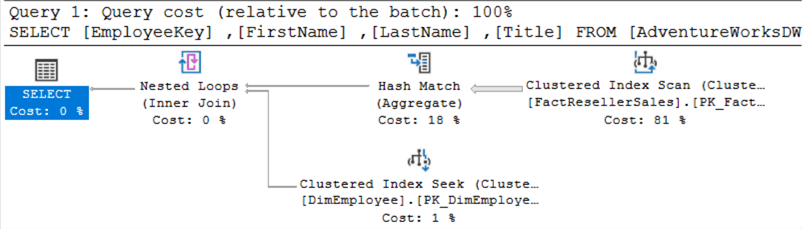
Dit is het plan voor IN:
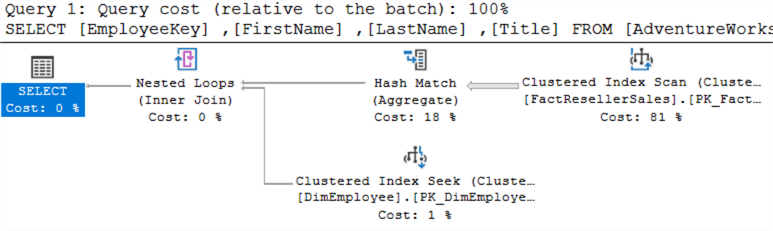
Ze zien er precies hetzelfde uit. Wanneer beide query’s tegelijkertijd worden uitgevoerd, zie je dat ze dezelfde kosten krijgen toegewezen:
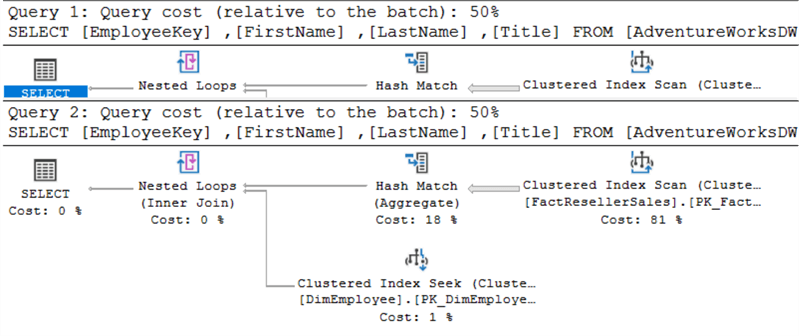
Het bovenste uitvoeringsplan is voor EXISTS, het onderste voor IN.
Laten we eens kijken naar de IO-statistieken (je kunt deze laten zien door het statement SET STATISTICS IO ON uit te voeren). Ook hier is alles precies hetzelfde:

Dus, er is geen verschil in prestaties dat we kunnen bewijzen en beide geven dezelfde resultatensets terug. Wanneer zou u de ene of de andere methode gebruiken? Hier volgen enkele richtlijnen:
- Als je een kleine lijst met statische waarden hebt (en de waarden staan niet in een of andere tabel), verdient de IN-operator de voorkeur.
- Als je moet controleren of er waarden in een andere tabel voorkomen, gebruik je bij voorkeur de EXISTS-operator, omdat die duidelijk aangeeft wat de bedoeling van de query is.
- Als je voor meer dan één kolom moet controleren, gebruik je bij voorkeur EXISTS, omdat je met de IN-operator slechts voor één kolom kunt controleren.
Laten we het laatste punt met een voorbeeld illustreren. In het AdventureWorks datawarehouse hebben we een dimensie Employee. Sommige werknemers beheren een specifiek verkoopgebied:
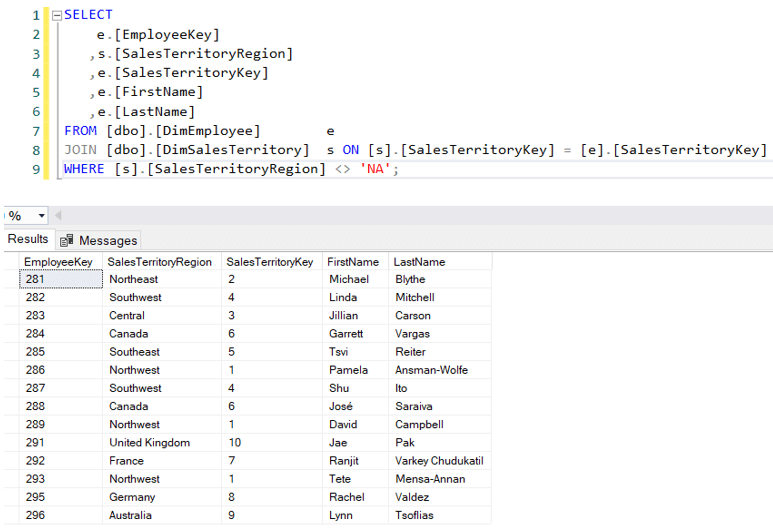
Nu is het mogelijk dat een verkoper ook in andere gebieden verkoopt.Michael Blythe bijvoorbeeld – verantwoordelijk voor de regio Noordoost – heeft in4 verschillende regio’s verkocht:
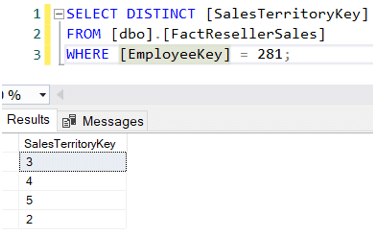
Laten we nu veronderstellen dat we alleen de verkoopbedragen voor de managers van de verkoopregio’s willen vinden, maar alleen voor hun eigen regio. Een mogelijke query zou kunnen zijn:
SELECT f. ,f. ,SUM()FROM . fWHERE EXISTS ( SELECT 1 FROM . e WHERE f. = e. AND f. = e. AND e. <> 11 -- the NA region )GROUP BY f. ,f.;
Het resultaat is als volgt:
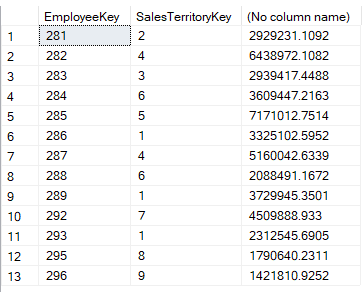
Binnen de EXISTS-clausule halen we de managers van de verkoopgebieden op door alle werknemers die aan de NA-regio zijn gekoppeld eruit te filteren. In de buitenste query krijgen we alle verkopen per verkoopgebied en werknemer, waarbij de werknemer en het gebied in de binnenste query zijn gevonden. Zoals u ziet, kunnen we met EXISTS eenvoudig controleren op meerdere kolommen, wat niet mogelijk is met IN.
SQL Server NOT IN vs NOT EXISTS
Door de operatoren te laten voorafgaan door de NOT operator, ontkrachten we de Booleaanse uitvoer van die operatoren. Als u bijvoorbeeld NOT IN gebruikt, krijgt u alle rijen met een waarde die niet in een lijst kan worden gevonden.
Er is echter één speciaal geval: wanneer NULL-waarden in beeld komen. Als er een NULL-waarde in de lijst voorkomt, is de resultatenset leeg!
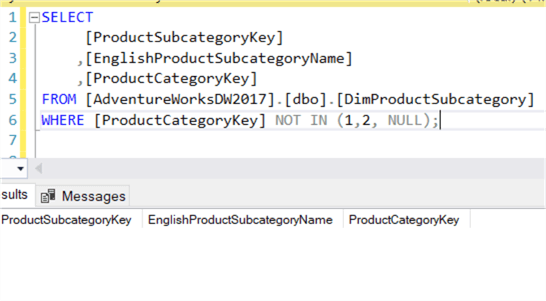
Dit betekent dat NOT IN onverwachte resultaten kan opleveren als er plotseling een NULL-waarde opduikt in de resultaatverzameling van de subquery. NOT EXISTS heeft dit probleem niet, omdat het niet uitmaakt wat er wordt geretourneerd. Als een lege resultaatverzameling wordt geretourneerd, zal NOT EXISTS dit ontkennen, wat betekent dat het huidige record niet wordt uitgefilterd:
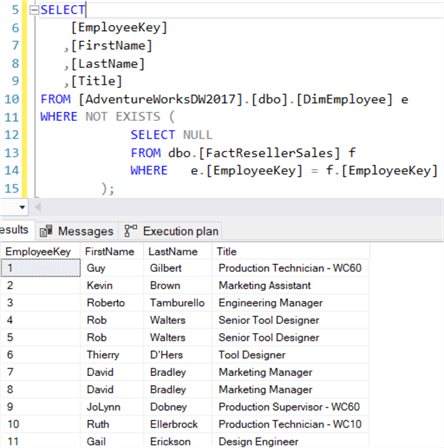
De bovenstaande query retourneert alle werknemers die nog geen verkoop hebben gedaan. Logischerwijs zijn NOT IN en NOT EXISTS hetzelfde – wat betekent dat ze dezelfde resultaten opleveren – zolang er geen NULLS bij betrokken zijn. Is er een verschil in prestatie? Nogmaals, beide queryplannen zijn hetzelfde:
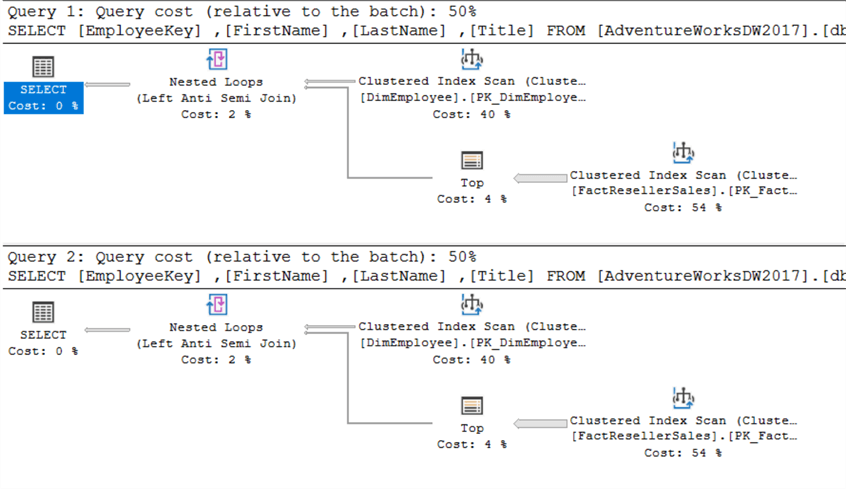
Hetzelfde geldt voor de IO-statistieken:
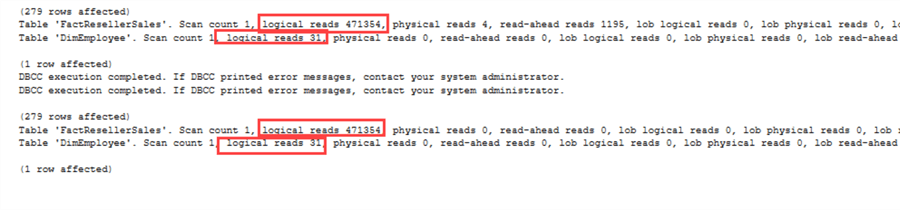
Er is echter één gotcha. De EmployeeKey is niet-nullable in FactResellerSales. Zoals eerder is aangetoond, kan NOT IN problemen opleveren wanneer er NULLs bij betrokken zijn. Als weEmployeeKey wijzigen zodat het wel nullaadbaar is, krijgen we de volgende uitvoeringsplannen:
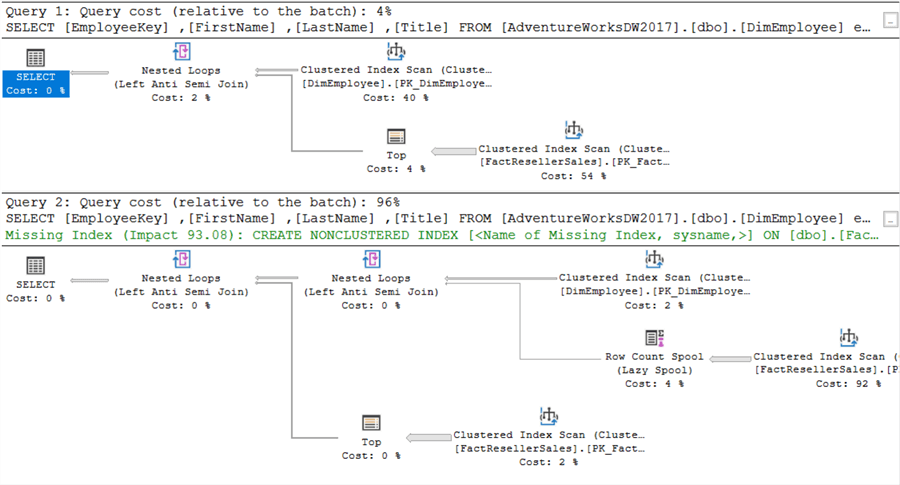
Een behoorlijk verschil deze keer! Omdat SQL Server nu rekening moet houden met NULL-waarden, verandert het uitvoeringsplan. Hetzelfde is te zien in de IO-statistieken:
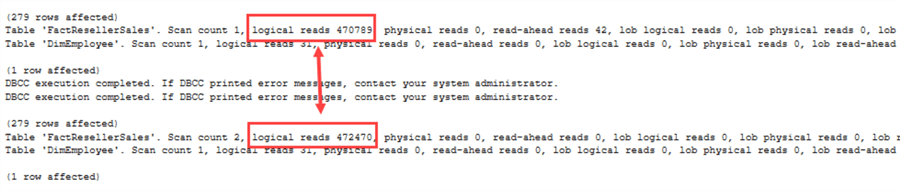
Nu is er een daadwerkelijk prestatieverschil tussen NOT IN en NOT EXISTS.Wanneer gebruik je welke operator? Enkele richtlijnen:
- Dezelfde richtlijnen als voor IN en EXISTS kunnen worden toegepast. Voor het controleren van een kleine statische lijst wordt de voorkeur gegeven aan NOT IN. Controleren op het bestaan in een andere tabel? NOT EXISTS is de betere keuze. Controleren op meerdere kolommen, ook hierNOT EXISTS.
- Als een van de kolommen nullable is, verdient NOT EXISTS de voorkeur.
Gebruik Joins in plaats van IN of EXISTS
Dezelfde logica kan ook met joins worden geïmplementeerd. Een alternatief voor IN enEXISTS is eenINNER JOIN, terwijl eenLEFT OUTER JOIN met een WHERE-clausule die controleert op NULL-waarden kan worden gebruikt als alternatief voor NOT IN en NOT EXISTS. De reden waarom ze niet in deze tip zijn opgenomen – ook al kunnen ze precies dezelfde resultatenreeks en hetzelfde uitvoeringsplan opleveren – is dat de bedoeling verschillend is. Met IN en EXISTS controleert u het bestaan van waarden in een andere recordverzameling. Met joins voeg je de resultatensets samen, wat betekent dat je toegang hebt tot alle kolommen van de andere tabel. Het controleren op het bestaan is meer een “neveneffect”. Wanneer je (NOT) IN en (NOT) EXISTS gebruikt, is het echt duidelijk wat de bedoeling van je query is. Joins daarentegen kunnen meerdere doelen hebben.
Door een INNER JOIN te gebruiken, kun je ook meerdere rijen voor dezelfde waarde laten terugkomen als er meerdere overeenkomsten zijn in de tweede tabel. Als je wilt controleren op bestaan en als een waarde bestaat heb je een kolom uit de andere tabel nodig, joins hebben de voorkeur.
Volgende Stappen
- Je kunt meer T-SQL tips vinden in dit overzicht.
- Gail Shaw, MVP van het eerste uur, heeft een aardige serie over EXISTS vs IN vs JOINS. Als je geïnteresseerd bent in het vergelijken van EXISTS/IN versus de JOINS, kun je de volgende blogposts lezen:
- IN vs INNER JOIN
- LEFT OUTER JOIN vs NOT EXISTS
- SQL Server Join Tips
- Tip:SQL Server Join Example
Laatst bijgewerkt: 2019-05-13


Over de auteur
 Koen Verbeeck is een BI professional, gespecialiseerd in de Microsoft BI stack met een bijzondere voorliefde voor SSIS.
Koen Verbeeck is een BI professional, gespecialiseerd in de Microsoft BI stack met een bijzondere voorliefde voor SSIS.Bekijk al mijn tips
- Meer Database Developer Tips…