Par : Koen Verbeeck | Mis à jour : 2019-05-13 | Commentaires (6) | Connexe : Plus de > T-SQL

Webinaire MSSQLTips gratuit : Meilleures pratiques de développement pour SQL Server
Assistez à ce webinaire pour découvrir les meilleures pratiques de développement pour SQL Server. Andy Warren partagera ses nombreuses années d’expérience pour donner quelques conseils sur ce qui a le mieux fonctionné pour lui et sur la façon dont vous pouvez utiliser certaines de ces connaissances.
Problème
Y a-t-il une différence entre l’utilisation de l’opérateur T-SQL IN ou de l’opérateur EXISTSdans une clause WHERE pour filtrer des valeurs spécifiques ? Y a-t-il une différence logique, une différence de performance ou sont-ils exactement les mêmes ? Et qu’en est-il de NOT IN etNOT EXISTS ?
Solution
Dans cette astuce, nous allons rechercher s’il existe des différences entre l’opérateurEXISTS et l’opérateur IN. Cela peut être soit logique, c’est-à-dire qu’ils se comportent différemment dans certaines circonstances, soit au niveau des performances, c’est-à-dire si l’utilisation d’un opérateur présente un avantage de performance par rapport à l’autre. Nous utiliserons le logicielAdventureWorks DW 2017 pour nos requêtes de test.
SQL Server IN vs EXISTS
L’opérateur IN est généralement utilisé pour filtrer une colonne pour une certaine liste de valeurs.Par exemple :
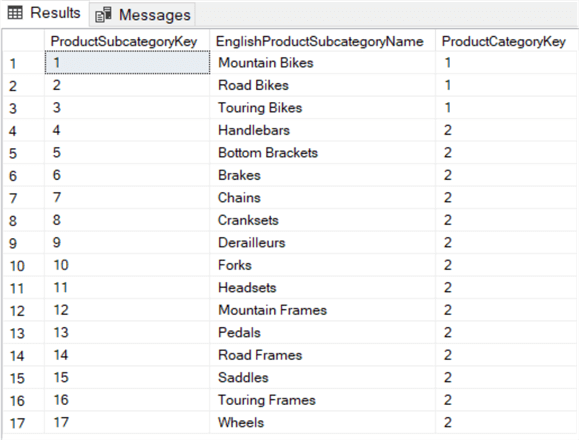
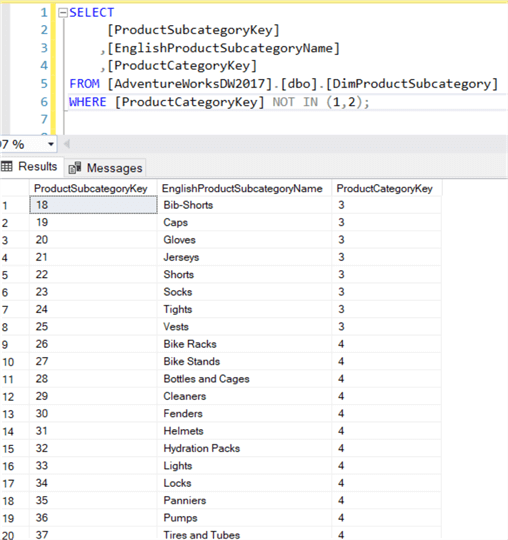
SELECT , ,FROM ..WHERE IN (1,2);
Cette requête recherche toutes les sous-catégories de produits qui appartiennent aux productcategories Bikes et Categories (ProductCategoryKey 1 et 2).
Vous pouvez également utiliser l’opérateur IN pour rechercher les valeurs dans le jeu de résultats de asubquery :
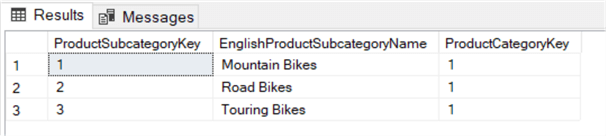
SELECT , ,FROM ..WHERE IN ( SELECT FROM . WHERE = 'Bikes' );
Cette requête renvoie toutes les sous-catégories liées à la catégorie Vélos.
L’avantage d’utiliser une sous-requête est que la requête devient moins codée en dur ; si la ProductCategoryKey change pour une raison quelconque, la deuxième requête fonctionnera toujours,alors que la première requête pourrait soudainement renvoyer des résultats incorrects. Il est importantque la sous-requête renvoie exactement une colonne pour que l’opérateur IN fonctionne.
L’opérateurEXISTS ne vérifie pas les valeurs, mais vérifie plutôt l’existencede lignes. Généralement, une sous-requête est utilisée en conjonction avec EXISTS. En fait, peu importe ce que la sous-requête renvoie, tant que des lignes sont renvoyées.
Cette requête renverra toutes les lignes de la table ProductSubcategory, car la sous-requête interne renvoie des lignes (qui ne sont pas du tout liées à la requête externe).
SELECT , ,FROM ..WHERE EXISTS ( SELECT 1/0 FROM . WHERE = 'Bikes' );
Comme vous avez pu le remarquer, la sous-requête a 1/0 dans la clause SELECT. Dans une requête normale, cela renverrait une erreur de division par zéro, mais dans une clause EXISTS, cela ne pose aucun problème, puisque cette division n’est jamais calculée. Cela démontre qu’il n’est pas important de savoir ce que la sous-requête renvoie, tant que des lignes sont renvoyées.
Pour utiliser EXISTS de manière plus significative, vous pouvez utiliser une sous-requête corrélée.Dans une sous-requête corrélée, nous couplons les valeurs de la requête externe avec les valeurs de la (sous-)requête interne. Cela permet de vérifier si la valeur de la requête externe existe dans la table utilisée dans la requête interne. Par exemple, si nous voulons retourner une liste de tous les employés qui ont fait une vente, nous pouvons écrire la requête suivante :
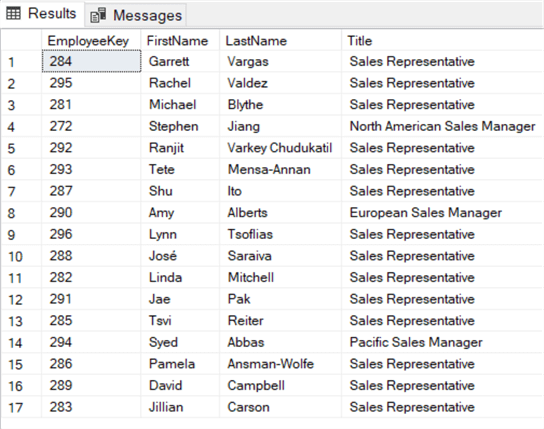
SELECT , , ,FROM .. eWHERE EXISTS ( SELECT 1 FROM dbo. f WHERE e. = f. );
Dans la clause WHERE à l’intérieur de la sous-requête EXISTS, nous corrélons la clé d’employé de la table externe – DimEmployee – avec la clé d’employé de la table interne – FactResellerSales. Si la clé d’employé existe dans les deux tables, une ligne est retournée et EXISTS renvoie true. Si une clé d’employé n’est pas trouvée dans FactResellerSales,EXISTS renvoie false et l’employé est omis des résultats :
Nous pouvons mettre en œuvre la même logique en utilisant l’opérateur IN :
SELECT , , ,FROM .. eWHERE IN ( SELECT FROM dbo. f );
Les deux requêtes renvoient le même ensemble de résultats, mais peut-être y a-t-il une différence de performance sous-jacente ? Comparons les plans d’exécution.
Voici le plan pour EXISTS:
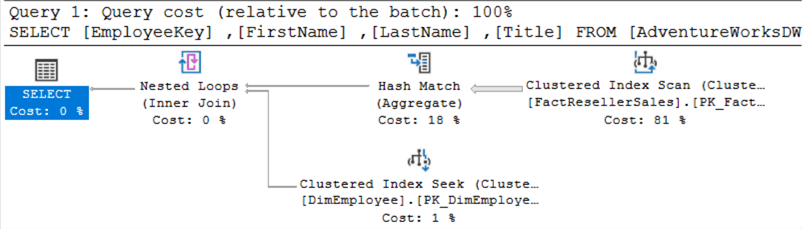
Voici le plan pour IN :
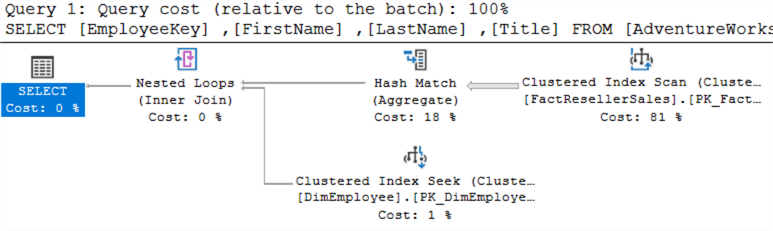
Ils ont exactement la même apparence. En exécutant les deux requêtes en même temps, vous pouvez voir qu’on leur attribue le même coût :
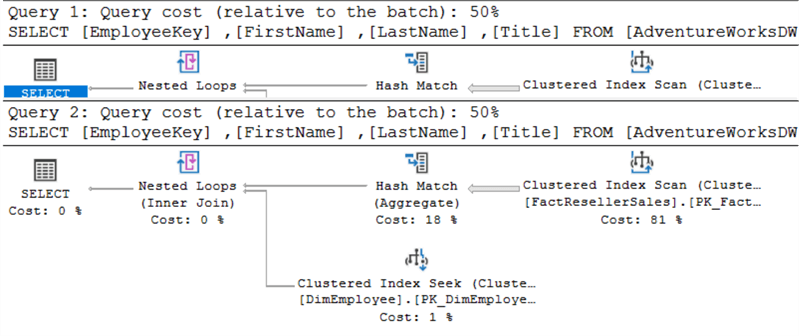
Le plan d’exécution du haut est pour EXISTS, celui du bas pour IN.
Regardons les statistiques IO (vous pouvez les afficher en exécutant l’instruction SET STATISTICS IO ON). Là encore, tout est exactement identique :

Donc, il n’y a pas de différence de performance que nous puissions prouver et les deux retournent les mêmes ensembles de résultats. Quand choisiriez-vous d’utiliser l’un ou l’autre ? Voici quelques lignes directrices :
- Si vous avez une petite liste de valeurs statiques (et que les valeurs ne sont pas présentes dans un certain tableau), l’opérateur IN est préférable.
- Si vous devez vérifier l’existence de valeurs dans une autre table, l’opérateur EXISTS est préféré car il démontre clairement l’intention de la requête.
- Si vous devez vérifier par rapport à plus d’une seule colonne, vous devez canoniquement utiliser EXISTS puisque l’opérateur IN ne vous permet de vérifier qu’une seule colonne.
Illustrons le dernier point avec un exemple. Dans le datawarehouse AdventureWorks, nous avons une dimension Employés. Certains employés gèrent un territoire de vente spécifique:
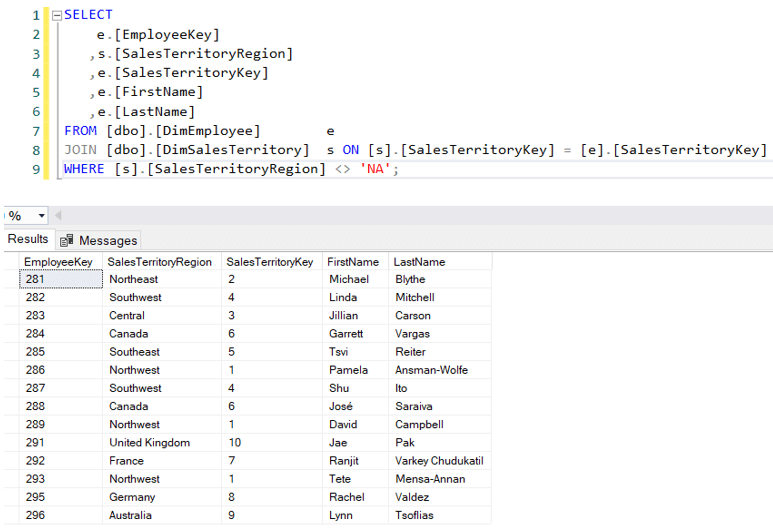
Maintenant, il est possible qu’un commercial réalise également des ventes dans d’autres territoires.Par exemple, Michael Blythe – responsable de la région Nord-Est – a vendu dans4 régions distinctes :
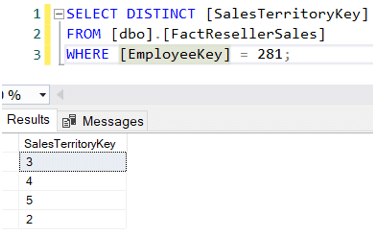
Supposons maintenant que nous ne voulons trouver que les montants des ventes des responsables salesterritoires, mais uniquement pour leur propre région. Une requête possible pourrait être:
SELECT f. ,f. ,SUM()FROM . fWHERE EXISTS ( SELECT 1 FROM . e WHERE f. = e. AND f. = e. AND e. <> 11 -- the NA region )GROUP BY f. ,f.;
Le résultat est le suivant:
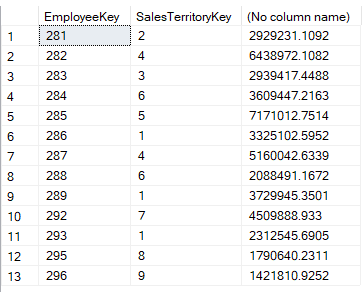
Dans la clause EXISTS, nous récupérons les gestionnaires de territoires de vente en filtrant tous les employés liés à la région NA. Dans la requête externe, nous obtenons toutes les ventes par territoire de vente et par employé, où l’employé et le territoire sont trouvés dans la requête interne. Comme vous pouvez le voir, EXISTS nous permet de vérifier facilement sur de multiples colonnes, ce qui n’est pas possible avec IN.
SQL Server NOT IN vs NOT EXISTS
En préfixant les opérateurs avec l’opérateur NOT, nous annulons la sortie booléenne de ces opérateurs. L’utilisation de NOT IN par exemple renverra toutes les lignes avec une valeur qui ne peut pas être trouvée dans une liste.
Il existe cependant un cas particulier : lorsque les valeurs NULL entrent en jeu. Si une valeur NULL est présente dans la liste, le jeu de résultats est vide !
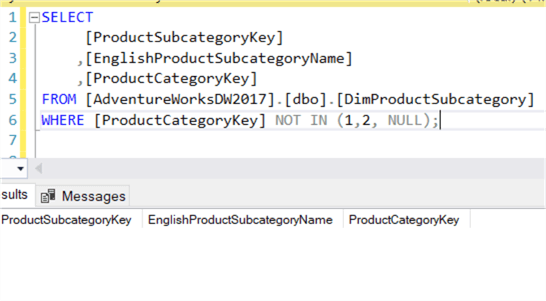
Cela signifie que NOT IN peut renvoyer des résultats inattendus si soudainement une valeur NULL surgit dans le jeu de résultats de la sous-requête. NOT EXISTS n’a pas ce problème, car ce qui est renvoyé n’a pas d’importance. Si un ensemble de résultats vide estrenvoyé, NOT EXISTS l’annulera, ce qui signifie que l’enregistrement actuel n’est pas filtré :
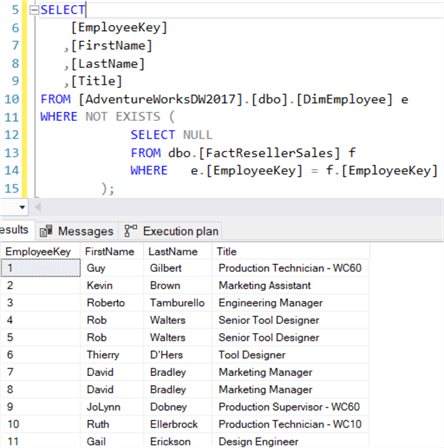
La requête ci-dessus renvoie tous les employés qui n’ont pas réalisé de vente. Logiquement, NOT IN et NOT EXISTS sont identiques – ce qui signifie qu’ils renvoient les mêmes ensembles de résultats – tant que les NULS ne sont pas impliqués. Y a-t-il une différence de performance ? Encore une fois, les deux plans de requête sont les mêmes :
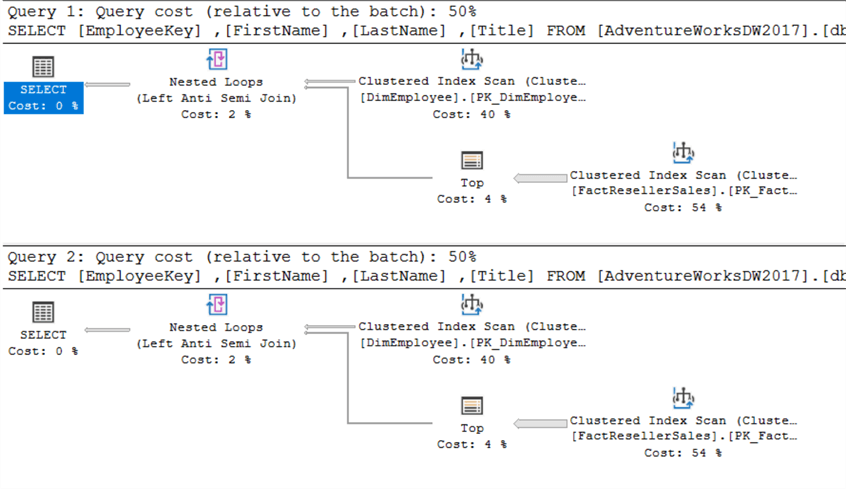
Il en va de même pour les statistiques IO :
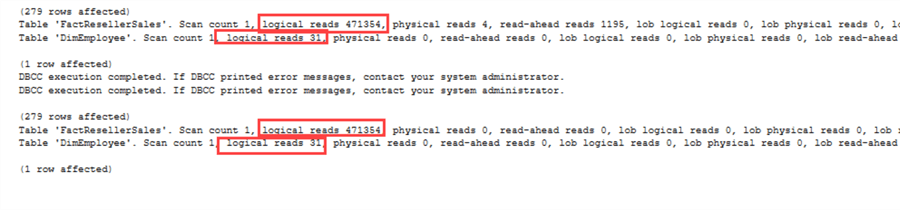
Il y a cependant un hic. Comme nous l’avons démontré précédemment, NOT IN peut poser des problèmes lorsque des NULL sont impliqués. Si nous changeonsEmployeeKey pour qu’il soit nullable, nous obtenons les plans d’exécution suivants :
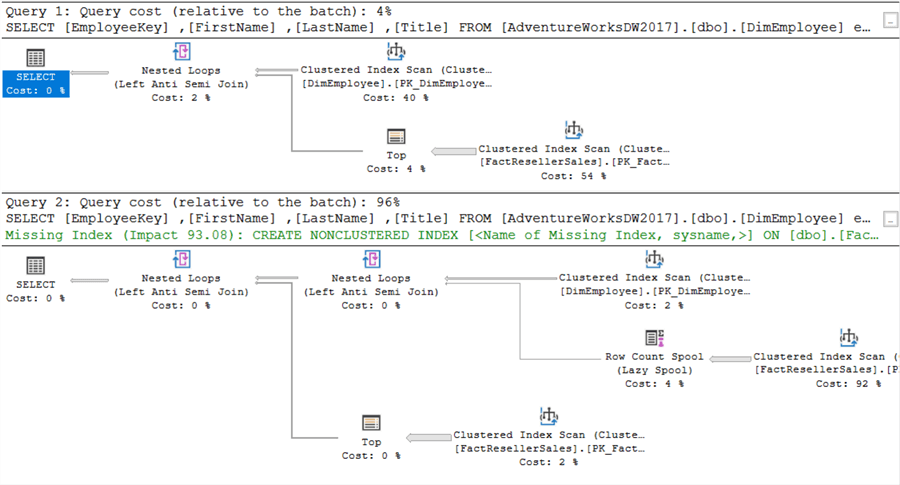
Quelle différence cette fois ! Parce que SQL Server doit maintenant prendre en compte les valeurs NULL, le plan d’exécution change. On peut observer la même chose dans les statistiques d’E/S:
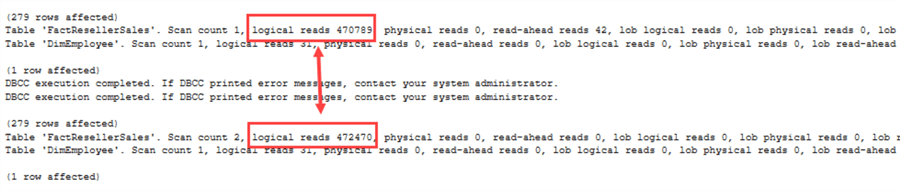
Maintenant, il y a une réelle différence de performance entre NOT IN et NOT EXISTS.Quand utiliser quel opérateur ? Quelques lignes directrices :
- Les mêmes directives que pour IN et EXISTS peuvent être appliquées. Pour la vérification par rapport à une petite liste statique, NOT IN est préférable. Pour vérifier l’existence dans une autre table ? NOT EXISTS est le meilleur choix. Vérification par rapport à plusieurs colonnes, là encore, NOT EXISTS.
- Si l’une des colonnes est nullable, NOT EXISTS est préférable.
Utilisation de jointures au lieu de IN ou EXISTS
La même logique peut être mise en œuvre avec des jointures également. Une alternative pour IN etEXISTS est uneINNER JOIN, tandis qu’uneLEFT OUTER JOIN avec une clause WHERE vérifiant les valeurs NULL peut être utilisée comme alternative pour NOT IN et NOT EXISTS. La raison pour laquelle ils ne sont pas inclus dans cette astuce – même s’ils peuvent retourner exactement le même ensemble de résultats et le même plan d’exécution – est que l’intention est différente. Avec IN et EXISTS, vous vérifiez l’existence de valeurs dans un autre jeu d’enregistrements. Avec les jointures, vous fusionnez les ensembles de résultats, ce qui signifie que vous avez accès à toutes les colonnes de l’autre table. Le contrôle de l’existence est plutôt un « effet secondaire ». Lorsque vous utilisez (NOT) IN et (NOT) EXISTS, l’intention de votre requête est vraiment claire. Les jointures, en revanche, peuvent avoir des objectifs multiples.
En utilisant un INNER JOIN, vous pouvez également avoir plusieurs lignes retournées pour la même valeur s’il y a plusieurs correspondances dans la deuxième table. Si vous voulez vérifier l’existenceet si une valeur existe, vous avez besoin d’une colonne de l’autre table, les jointures sont préférables.
Prochaines étapes
- Vous pouvez trouver plus de conseils T-SQL dans cetteoverview.
- Gail Shaw, MVP de longue date, propose une belle série sur EXISTS vs IN vs JOINS. Si vous êtes intéressé par la comparaison entre EXISTS/IN et JOINS, vous pouvez lire les articles suivants :
- IN vs INNER JOIN
- Left OUTER JOIN vs NOT EXISTS
- Conseils sur les jointures SQL Server
- Tip:SQL Server Join Example
Dernière mise à jour : 2019-05-13


.
À propos de l’auteur
 Koen Verbeeck est un professionnel de la BI, spécialisé dans la pile BI de Microsoft avec un amour particulier pour SSIS.
Koen Verbeeck est un professionnel de la BI, spécialisé dans la pile BI de Microsoft avec un amour particulier pour SSIS.Voir tous mes conseils
- Plus de conseils pour les développeurs de bases de données…
.