By Noel Bambrick, AYLIEN.
Wprowadzenie
W tym poście zamierzamy wprowadzić Cię do algorytmu uczenia maszynowego Support Vector Machine (SVM). Będziemy postępować podobnie do naszego ostatniego postu Naive Bayes for Dummies; A Simple Explanation, utrzymując go krótkim i nie przesadnie technicznym. Celem jest zapewnienie tym z Was, którzy są nowi w uczeniu maszynowym, podstawowego zrozumienia kluczowych pojęć tego algorytmu.
Maszyny Wektorów Wsparcia – Czym są?
Maszyna Wektorów Wsparcia (SVM) jest algorytmem uczenia maszynowego, który może być stosowany zarówno do klasyfikacji, jak i regresji. SVM są częściej używane do klasyfikacji i to na nich skupimy się w tym wpisie.
SVM opierają się na idei znalezienia hiperpłaszczyzny, która najlepiej dzieli zbiór danych na dwie klasy, jak pokazano na poniższym obrazku.
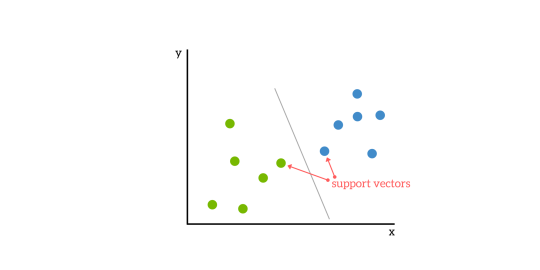
Wektory wsparcia
Wektory wsparcia to punkty danych najbliższe hiperpłaszczyźnie, punkty zbioru danych, których usunięcie zmieniłoby położenie hiperpłaszczyzny podziału. Z tego powodu mogą być uważane za krytyczne elementy zbioru danych.
Co to jest hiperpłaszczyzna?
Jako prosty przykład, dla zadania klasyfikacji z tylko dwoma cechami (jak obrazek powyżej), możesz myśleć o hiperpłaszczyźnie jako linii, która liniowo oddziela i klasyfikuje zbiór danych.
Intuicyjnie, im dalej od hiperpłaszczyzny leżą nasze punkty danych, tym bardziej jesteśmy pewni, że zostały poprawnie sklasyfikowane. Dlatego chcemy, aby nasze punkty danych znajdowały się jak najdalej od hiperpłaszczyzny, jednocześnie będąc po jej właściwej stronie.
Więc, gdy dodawane są nowe dane testowe, strona hiperpłaszczyzny, po której lądują, decyduje o klasie, którą im przypisujemy.
Jak znaleźć właściwą hiperpłaszczyznę?
Albo, innymi słowy, jak najlepiej posegregować dwie klasy w danych?
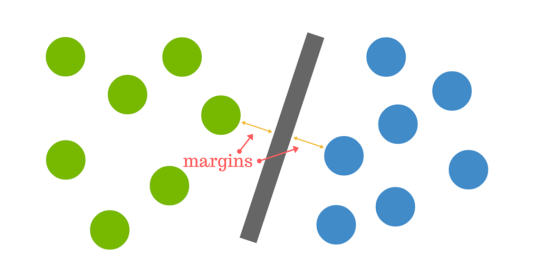
Dystans pomiędzy hiperpłaszczyzną a najbliższym punktem danych z obu zestawów nazywamy marginesem. Celem jest wybranie hiperpłaszczyzny z największym możliwym marginesem pomiędzy hiperpłaszczyzną a dowolnym punktem w zbiorze treningowym, co daje większą szansę na prawidłowe sklasyfikowanie nowych danych.
Ale co się dzieje, gdy nie ma wyraźnej hiperpłaszczyzny?
Tutaj może pojawić się problem. Dane rzadko kiedy są tak czyste jak nasz prosty przykład powyżej. Zbiór danych często będzie wyglądał bardziej jak pomieszane kulki poniżej, które reprezentują liniowo nierozdzielny zbiór danych.
 here.
here.
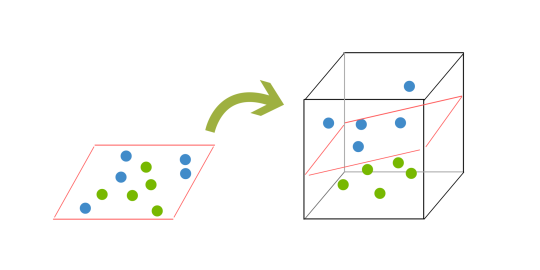
Ponieważ jesteśmy teraz w trzech wymiarach, nasza hiperpłaszczyzna nie może być już linią. Musi to być teraz płaszczyzna, jak pokazano w powyższym przykładzie. Chodzi o to, że dane będą nadal mapowane do coraz wyższych wymiarów, aż hiperpłaszczyzna może być utworzona, aby je posegregować.
Pros & Cons of Support Vector Machines
Pros
- Dokładność
- Dobrze sprawdza się na mniejszych, czystszych zbiorach danych
- Może być bardziej wydajna, ponieważ używa podzbioru punktów treningowych
Cons
- Nie nadaje się do większych zbiorów danych, ponieważ czas szkolenia z SVM może być wysoki
- Mniej efektywna na bardziej hałaśliwych zbiorach danych z nakładającymi się klasami
- How to Select Support Vector Machine Kernels
- When Does Deep Learning Work Better Than SVMs or Random Forests?
- Machine Learning Key Terms, Explained
Przykłady
Użycia SVM
SVM jest używana do zadań klasyfikacji tekstu, takich jak przypisywanie kategorii, wykrywanie spamu i analiza sentymentu. Jest również powszechnie używana do rozpoznawania obrazów, szczególnie dobrze radząc sobie w rozpoznawaniu aspektów i klasyfikacji opartej na kolorach. SVM odgrywa również istotną rolę w wielu obszarach rozpoznawania pisma ręcznego, takich jak usługi automatyzacji poczty.
Tutaj masz to, bardzo wysoki poziom wprowadzenia do Support Vector Machines. Jeśli chciałbyś zagłębić się w SVM, polecamy sprawdzić (musisz znaleźć link do wideo lub bardziej szczegółowego bloga).
About: Ten blog został pierwotnie opublikowany na blogu AYLIEN Text Analysis. AYLIEN dostarcza narzędzia i usługi, aby pomóc programistom i naukowcom w tworzeniu treści niestrukturalnych w skali.
Oryginał. Reposted with permission.
Related:
.