Co to jest skala Likerta?
Statystyka Definicje >
Co to jest skala Likerta?
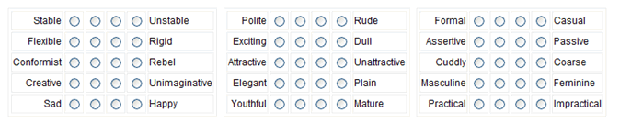
Odmiany skali Likerta.
Skala Likerta jest rodzajem skali ocen używanej do pomiaru postaw lub opinii. W tej skali respondenci są proszeni o ocenę pozycji na podstawie poziomu zgodności. Na przykład:
- Bardzo się zgadzam
- Zgadza się
- Neutralny
- Nie zgadza się
- Bardzo się nie zgadzam
W skali zwykle stosuje się od pięciu do siedmiu pozycji. Skala nie musi zawierać stwierdzenia „zgadzam się” lub „nie zgadzam się”; możliwe są dziesiątki wariantów na tematy takie jak zgoda, częstotliwość, jakość i ważność. Na przykład:
- Zgoda: Zdecydowanie się zgadzam do Zdecydowanie się nie zgadzam.
- Częstotliwość: Często do nigdy.
- Jakość: Bardzo dobra do bardzo złej.
- Prawdopodobieństwo: Zdecydowanie do nigdy.
- Znaczenie: Bardzo ważne do nieistotne.
Te pozycje nazywamy kotwicami odpowiedzi w skali Likerta.
Po udzieleniu odpowiedzi przez respondentów, odpowiedziom przypisywane są numery. Na przykład:
Bardzo się zgadzam=5
Zgadzam się=4
Neutralny=3
Nie zgadzam się=2
Bardzo się nie zgadzam=1
To pozwala Ci przypisać znaczenie do odpowiedzi. Na przykład, ankieta dotycząca obsługi klienta może pozwolić Ci sprawdzić, którzy z Twoich przedstawicieli obsługi klienta świadczą usługi na dobrym poziomie (średnia ocen 4-5), a którzy na złym (średnia ocen 1-2).
Kroki do stworzenia skali Likerta
- Zdefiniuj punkt ciężkości: co próbujesz zmierzyć? Twój temat powinien być jednowymiarowy. Na przykład „Obsługa klienta” lub „Ta strona internetowa.”
- Wygeneruj elementy skali Likerta. Pozycje powinny być w stanie być oceniane na jakiejś skali. Obrazek na górze tej strony ma kilka sugestii. Na przykład, uprzejmy/nieuprzejmy może być oceniany jako „bardzo uprzejmy”, „uprzejmy”, „nieuprzejmy” lub „bardzo nieuprzejmy”. Uprzejmość może być również oceniana w skali od 1 do 10, gdzie 1 nie jest w ogóle uprzejmy i 10 jest bardzo uprzejmy.
- Oceń elementy skali Likerta. Chcesz mieć pewność, że Twoja koncentracja jest dobra, więc wybierz zespół ludzi, którzy przejdą przez pozycje z kroku 2 powyżej i ocenią je jako korzystne/neutralne/niekorzystne dla Twojej koncentracji. Wyeliminuj te elementy, które są najczęściej postrzegane jako niekorzystne.
- Przeprowadź test na skali Likerta.
Testy hipotez na skalach Likerta
Jeśli wiesz, że będziesz przeprowadzał analizę danych na skali Likerta, łatwiej jest dostosować pytania w fazie rozwoju, niż zbierać dane, a następnie podjąć decyzję o analizie. To, jaką analizę przeprowadzisz, zależy od formatu Twojego kwestionariusza.
W edukacji i badaniach naukowych nie ma zgody co do tego, czy na danych w skali Likerta powinieneś przeprowadzać testy parametryczne, takie jak t-test, czy nieparametryczne testy hipotez, takie jak Mann-Whitney. Winter i Dodou(2010) zbadali tę kwestię, uzyskując następujące wyniki:
„Podsumowując, test t i ogólnie mają równoważną moc, z wyjątkiem rozkładów skośnych, szczytowych lub wielomodalnych, dla których wystąpiły silne różnice w mocy obu testów. Wskaźnik błędu typu I dla obu metod nigdy nie był wyższy niż 3% powyżej nominalnego wskaźnika 5%, nawet nie wtedy, gdy liczebność próby była bardzo nierówna.”
Innymi słowy, wydaje się, że nie ma prawdziwej różnicy między wynikami dla testów parametrycznych i nieparametrycznych, z wyjątkiem rozkładów skośnych, szczytowych lub wielomodalnych. To, którą drogę wybierzesz, zależy od Ciebie, Twojego działu i być może czasopisma, do którego składasz pracę (jeśli w ogóle). Najważniejszym krokiem na etapie podejmowania decyzji jest określenie, czy dane mają być traktowane jako dane porządkowe czy przedziałowe. Następnie należy zapoznać się z poniższą sekcją dotyczącą danego typu danych. Kilka ogólnych wskazówek:
- Dla serii indywidualnych pytań z odpowiedziami Likerta, traktuj dane jako zmienne porządkowe.
- Dla serii pytań Likerta, które razem opisują pojedynczy konstrukt (cechę osobowości lub postawę), traktuj dane jako zmienne interwałowe.
Dwie opcje
Większość skal Likerta jest klasyfikowana jako zmienne porządkowe. Jeśli jesteś w 100% pewien, że odległość między zmiennymi jest stała, wtedy mogą one być traktowane jako zmienne interwałowe do celów testowych. W większości przypadków Twoje dane będą porządkowe, ponieważ nie jest możliwe określenie różnicy pomiędzy, powiedzmy, „zdecydowanie zgadzam się” i „zgadzam się” vs. „zgadzam się” i „neutralny.”
Dane ze skali porządkowej
W przypadku większości typów zmiennych (interwał, stosunek, nominalny), możesz znaleźć średnią. Nie jest to prawdą dla danych w skali Likerta. Średnia w skali Likerta nie może być znaleziona, ponieważ nie znasz „odległości” pomiędzy pozycjami danych. Innymi słowy, podczas gdy można znaleźć średnią z 1,2 i 3, nie można znaleźć średniej z „zgadzam się”, „nie zgadzam się” i „neutralny”.
„Średnia z 'fair' i 'good' nie jest 'fair-and-a-half'; co jest prawdą nawet wtedy, gdy przypisuje się liczby całkowite do reprezentowania 'fair' i 'good'!” – Susan Jamieson parafrazując Kuzon Jr et al. (Jamieson, 2004)
Wybory statystyk
Statystyki, których możesz użyć to:
- Tryb: najczęstsza odpowiedź.
- Mediana: „środkowa” odpowiedź, gdy wszystkie elementy są ułożone w kolejności.
- Rozstęp i przedział międzykwartylowy: aby pokazać zmienność.
- Wykres słupkowy lub tabela częstotliwości: aby pokazać tabelę wyników. Nie rób histogramu, ponieważ dane nie są ciągłe.
Testowanie hipotez
W testowaniu hipotez dla skal Likerta, zmienna niezależna reprezentuje grupy, a zmienna zależna reprezentuje konstrukt, który mierzysz. Na przykład, jeśli badasz studentów pielęgniarstwa, aby zmierzyć ich poziom współczucia, zmienną niezależną są grupy studentów pielęgniarstwa, a zmienną zależną jest poziom współczucia.
Typy testów, które można przeprowadzić:
- Test Kruskala Wallisa: określa, czy mediany dla dwóch grup są różne.
- Test U Manna Whitneya: określa, czy mediany dla dwóch grup są różne. Łatwy do oceny pojedynczych pytań w skali Likerta, ale cierpi z powodu kilku form tendencyjności, w tym tendencyjności centralnej, tendencyjności przyzwolenia i tendencyjności społecznej. Ponadto, ważność jest zazwyczaj trudna do wykazania.
Więcej opcji dla dwóch kategorii
Jeśli połączysz swoje odpowiedzi w dwie kategorie, na przykład, zgadzam się i nie zgadzam się, otwiera się przed Tobą więcej opcji testowych.
- Chi-kwadrat: Test przeznaczony jest do eksperymentów wielomianowych, gdzie wyniki są zliczane w kategoriach.
- Test McNemara: Testuje, czy odpowiedzi na kategorie są takie same dla dwóch grup/warunków.
- Test Cochrana Q: Rozszerzenie testu McNemara, który sprawdza, czy odpowiedzi na kategorie są takie same dla trzech lub więcej grup/warunków.
- Test Friedmana: dla znalezienia różnic w leczeniu w wielu próbach.
Measures of Association
Czasami chcesz wiedzieć, czy jedna grupa ludzi ma inną odpowiedź (wyższą lub niższą) niż inna grupa ludzi na pewien element skali Likerta. Aby odpowiedzieć na to pytanie, użyjesz miary asocjacji zamiast testu różnic (jak te wymienione powyżej).
Jeśli twoje grupy są porządkowe (tj. uporządkowane) w jakiś sposób, jak np. grupy wiekowe, możesz użyć:
- Współczynnik tau Kendalla lub jego warianty (np. współczynnik gamma; D Somersa).
- Spearman rank correlation.
Jeśli Twoje grupy nie są porządkowe, użyj jednego z poniższych:
- Współczynnik Phi.
- Współczynnik kontyngencji.
- Współczynnik V Cramera.
Dane w skali interwałowej
Statystyki, które są odpowiednie dla danych w skali interwałowej Likerta:
- Średnia.
- Odchylenie standardowe.
Testy hipotez odpowiednie dla danych Likerta w skali interwałowej:
- Test T.
- ANOVA.
- Analiza regresji (uporządkowana regresja logistyczna lub wielomianowa regresja logistyczna). Jeśli możesz połączyć zmienne zależne w dwie odpowiedzi (np. zgadzam się lub nie zgadzam się), uruchom binarną regresję logistyczną.
——————————————————————————
Potrzebujesz pomocy z zadaniem domowym lub pytaniem testowym? Dzięki Chegg Study możesz uzyskać rozwiązania krok po kroku na swoje pytania od eksperta w danej dziedzinie. Pierwsze 30 minut z korepetytorem Chegg jest bezpłatne!