By: Koen Verbeeck | Actualizado: 2019-05-13 | Comentários (6) | Related: Mais > T-SQL
Webinar de Dicas MSSQLTips gratuitas: Melhores Práticas de Desenvolvimento para SQL Server
Participar neste webinar para aprender sobre as melhores práticas de desenvolvimento para SQL Server. Andy Warren partilhará os seus muitos anos de experiência para dar algumas indicações sobre o que funcionou melhor para ele e como pode utilizar alguns destes conhecimentos.
Problem
Existe uma diferença entre utilizar o operador T-SQL IN ou o operador EXISTS numa cláusula WHERE para filtrar para valores específicos? Existe uma diferença lógica, uma diferença de desempenho ou são exactamente os mesmos? E quanto ao NOT IN e NOT EXISTS?
Solução
Nesta dica vamos investigar se existem quaisquer diferenças entre o operador EXISTS e o operador IN. Isto pode ser lógico, ou seja, eles comportam-se de forma diferente em determinadas circunstâncias, ou em termos de desempenho, ou seja, se a utilização de um operador tem um benefício de desempenho em relação ao outro. Vamos utilizar aAdventureWorks DW 2017 para as nossas consultas de teste.
SQL Server IN vs EXISTS
TheIN operator is typically used to filter a column for a certain list of values.For example:
SELECT , ,FROM ..WHERE IN (1,2);
Esta consulta procura todas as subcategorias de produtos que pertencem às categorias de produtos Bicicletas e Categorias (ProductCategoryKey 1 e 2).
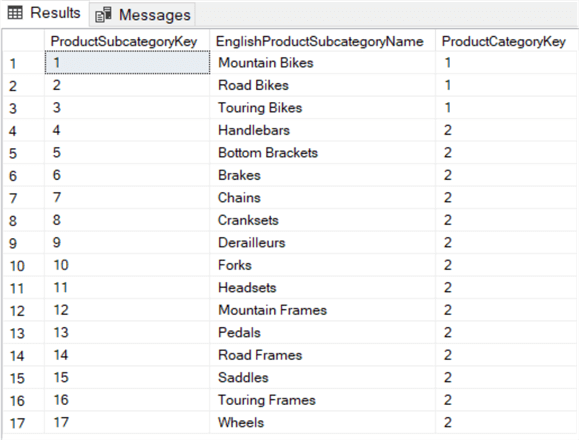
P>Pode também usar o operador IN para pesquisar os valores no conjunto de resultados de asubquery:
SELECT , ,FROM ..WHERE IN ( SELECT FROM . WHERE = 'Bikes' );
Esta consulta devolve todas as subcategorias ligadas à categoria Bicicletas.
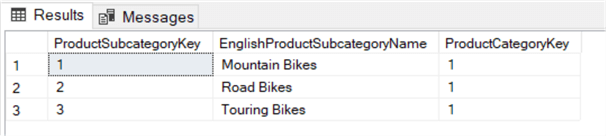
O benefício de utilizar uma subconsulta é que a consulta se torna menos codificada; se a chave da categoria do produto mudar por alguma razão, a segunda consulta ainda funcionará, enquanto que a primeira consulta pode subitamente retornar resultados incorrectos. É importante embora a subconsulta devolva exactamente uma coluna para o operador IN funcionar.
O operadorEXISTS não verifica a existência de valores, mas verifica a existência de filas. Tipicamente, uma subconsulta é usada em conjunto com o EXISTS. Na realidade, não importa o que a subconsulta retorna, desde que as linhas sejam devolvidas.
Esta consulta retornará todas as linhas da tabela de Subcategoria de Produto, porque a subconsulta de vencedor retorna linhas (que não estão de todo relacionadas com a consulta externa).
SELECT , ,FROM ..WHERE EXISTS ( SELECT 1/0 FROM . WHERE = 'Bikes' );
Como deve ter notado, a subconsulta tem 1/0 na cláusula SELECT. Numa consulta normal, isto devolveria uma divisão por erro zero, mas dentro de uma cláusula EXISTS éperfeitamente fina, uma vez que esta divisão nunca é calculada. Isto demonstra que não é importante o que a subconsulta retorna, desde que as linhas sejam devolvidas.
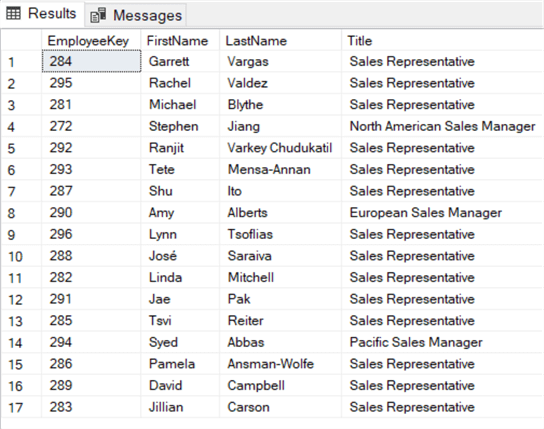
Para usar EXISTS de uma forma mais significativa, pode usar uma subconsulta correlacionada.Numa subconsulta correlacionada, emparelhamos valores da consulta externa com valores da (sub)consulta do vencedor. Isto verifica efectivamente se o valor da consulta externa existe na tabela utilizada na consulta interna. Por exemplo, se quisermos devolver uma lista de todos os empregados que fizeram uma venda, podemos escrever a seguinte consulta:
SELECT , , ,FROM .. eWHERE EXISTS ( SELECT 1 FROM dbo. f WHERE e. = f. );
Na cláusula WHERE dentro da subconsulta EXISTS, correlacionamos a chave do empregado da tabela externa – DimEmployee – com a chave do empregado da tabela interna – FactResellerSales. Se a chave de empregado existir em ambas as tabelas, um remo é devolvido e EXISTS retornará verdadeiro. Se uma chave de funcionário não for encontrada em FactResellerSales,EXISTS devolve falsa e o funcionário é omitido dos resultados:
Podemos implementar a mesma lógica usando o operador IN:
SELECT , , ,FROM .. eWHERE IN ( SELECT FROM dbo. f );
As duas consultas retornam o mesmo conjunto de resultados, mas talvez haja uma diferença de desempenho subjacente? Vamos comparar os planos de execução.
Este é o plano para EXISTS:
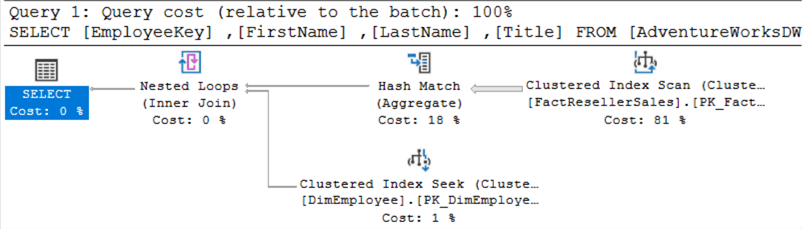
Este é o plano para IN:
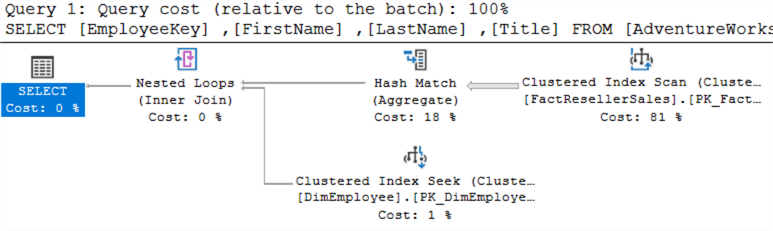
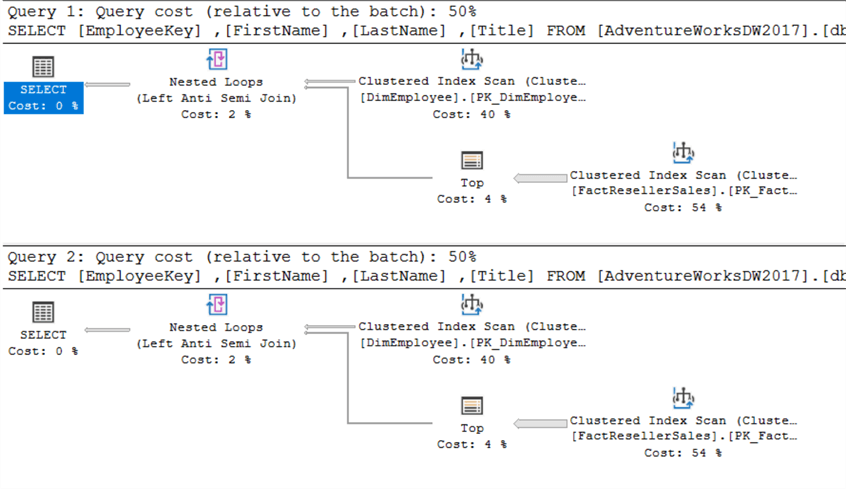
Têm exactamente o mesmo aspecto. Ao executar ambas as consultas ao mesmo tempo, é possível ver que lhes é atribuído o mesmo custo:
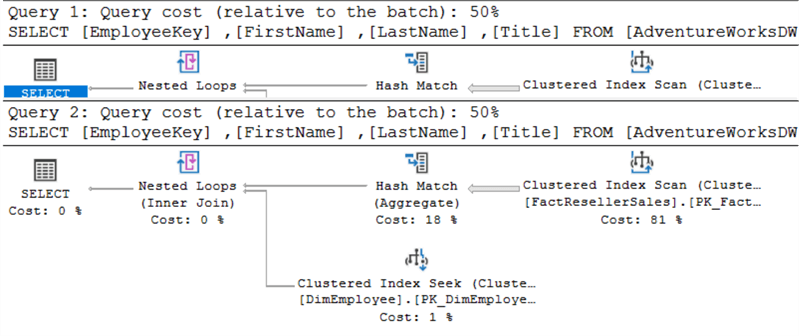
O plano de execução superior é para EXISTS, o plano inferior para IN.
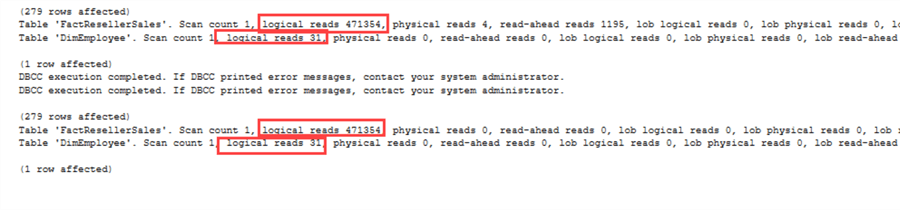
Demos uma vista de olhos às estatísticas IO (pode mostrá-las executando o thestatement SET STATISTICS IO ON). Mais uma vez, tudo é exactamente o mesmo:

Então, não há diferença de desempenho que possamos provar e ambos retornam os mesmos conjuntos de resultados. Quando escolheria usar um ou outro? Aqui estão algumas directrizes:
- Se tiver uma pequena lista de valores estáticos (e os valores não estão presentes em alguma tabela), o operador IN é o preferido.
- Se precisar de verificar a existência de valores noutra tabela, o operador EXISTS é preferível, pois demonstra claramente a intenção da consulta.
- Se precisar de verificar a existência de mais do que uma única coluna, só pode usar EXISTS, pois o operador IN só permite verificar a existência de uma única coluna.
Vamos ilustrar o último ponto com um exemplo. No datawarehouse da AdventureWorks, temos uma dimensão de Empregado. Alguns empregados gerem um território específico:
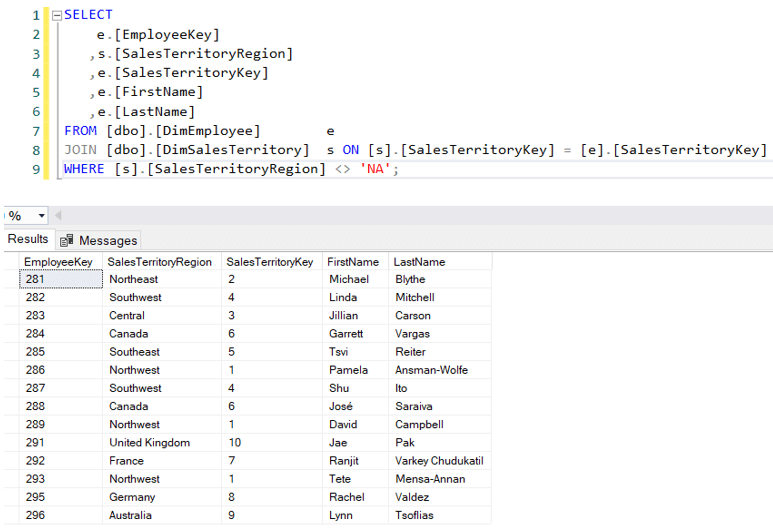
Agora, é possível que um vendedor também faça vendas noutros territórios.Por exemplo, Michael Blythe – responsável pela região Nordeste – já vendeu em4 regiões distintas:
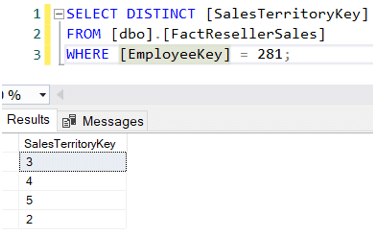
Só queremos agora encontrar os montantes das vendas para os gerentes dos vendedores, mas apenas para a sua própria região. Uma possível consulta poderia ser:
SELECT f. ,f. ,SUM()FROM . fWHERE EXISTS ( SELECT 1 FROM . e WHERE f. = e. AND f. = e. AND e. <> 11 -- the NA region )GROUP BY f. ,f.;
O resultado é o seguinte:
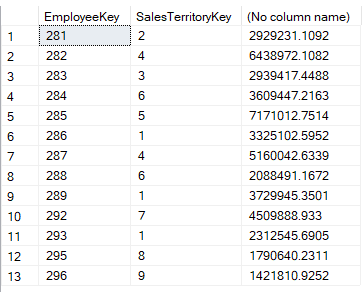
Dentro da cláusula EXISTS, recuperamos os gerentes dos territórios de vendas filtrando todos os empregados ligados à região NA. Na consulta externa, obtemos todas as vendas por território de vendas e empregado, onde o empregado e território é encontrado na consulta interna. Como pode ver, EXISTS permite-nos verificar facilmente as colunas múltiplas, o que não é possível com IN.
SQL Server NOT IN vs NOT EXISTS
Ao prefixarmos os operadores com o operador NOT, negamos o resultado Booleano desses operadores. Usando NOT IN, por exemplo, devolveremos todas as linhas com um valor que não pode ser encontrado numa lista.
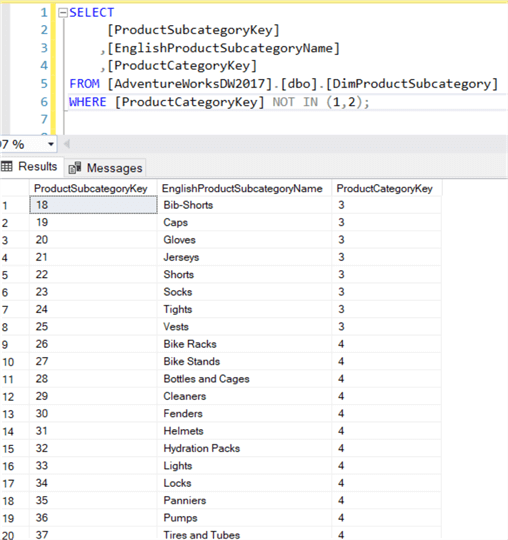
Há um caso especial no entanto: quando os valores NULL entram em cena. O valor NULL está presente na lista, o conjunto de resultados está vazio!
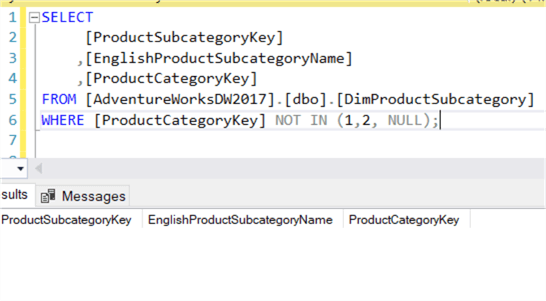
Isso significa que NOT IN pode retornar resultados inesperados se, de repente, um valor NULL aparecer no conjunto de resultados da subconsulta. NOT EXISTS não tem esta questão, uma vez que não importa o que é devolvido. Se um conjunto de resultados vazio for devolvido, NOT EXISTS negará isto, o que significa que o registo actual não é filtrado:
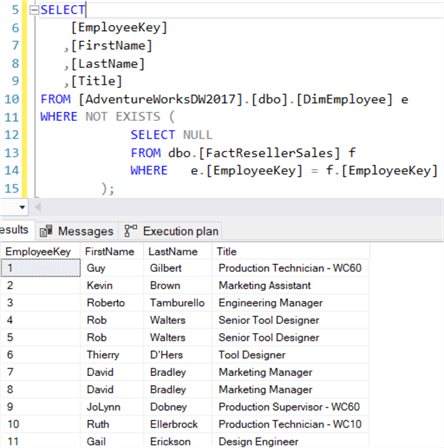
A consulta acima devolve todos os empregados que não fizeram uma venda. Logicamente,NOT IN e NOT EXISTS são os mesmos – o que significa que devolvem os mesmos conjuntos de resultados – desde que não estejam envolvidos NULLS. Existe alguma diferença de desempenho? Mais uma vez, ambos os planos de consulta são os mesmos:
O mesmo acontece com as estatísticas IO:
Há, no entanto, um que se tem. A EmployeeKey não é nula em FactResellerSales. Como demonstrado anteriormente, NOT IN pode ter problemas quando NULLs estão envolvidos. Se mudarmosEmployeeKey para ser anulável, obtemos os seguintes planos de execução:
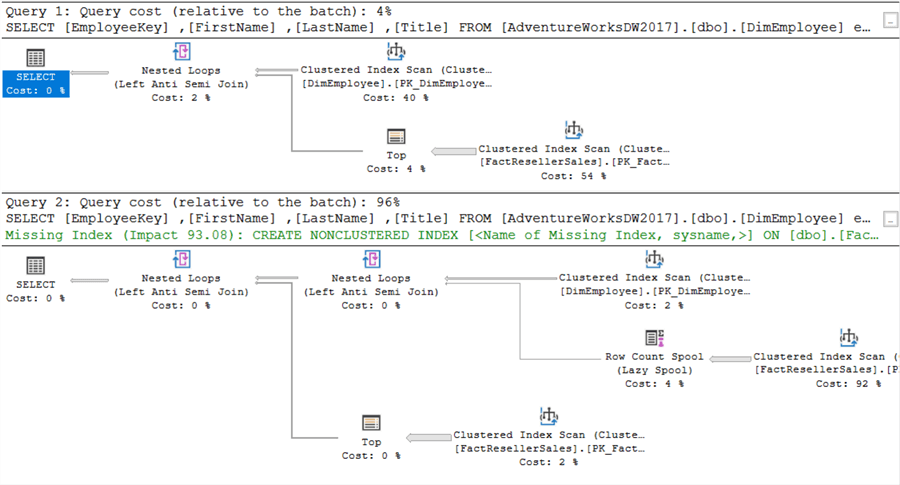
Quite a difference this time! Porque o SQL Server tem agora de levar em conta valores NULL, o plano de execução muda. O mesmo pode ser visto nas estatísticas IO:
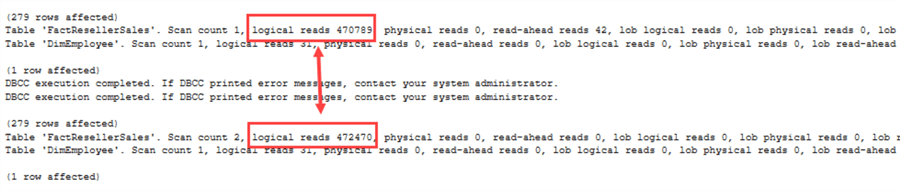
Agora há uma diferença real de desempenho entre NOT IN e NOT EXISTS.Quando utilizar qual o operador? Algumas directrizes:
- As mesmas directrizes que para IN e EXISTS podem ser aplicadas. Para verificar novamente uma pequena lista estática, é preferível NOT IN. Verificar a existência noutra mesa? NOT EXISTS é a melhor escolha. Verificando contra múltiplas colunas, novamenteNÃO EXISTEM.
- Se uma das colunas for nula, NÃO EXISTE é preferida.
Usar Junções em vez de IN ou EXISTS
A mesma lógica também pode ser implementada com junções. Uma alternativa para o IN andEXISTS é o ININNER JOIN, enquanto que o OUTER OUTER JOIN com uma cláusula ONDE a verificação dos valores NULL pode ser utilizada como analternativa para o NOT IN e NOT EXISTS. A razão pela qual não estão incluídos nesta ponta – ainda que possam devolver exactamente o mesmo conjunto de resultados e plano de execução – é porque a intenção é diferente. Com IN e EXISTS, verifica-se a existência de valores num outro conjunto de registos. Com as uniões, fundem-se os conjuntos de resultados, o que significa que se tem acesso a todas as colunas da outra tabela. A verificação da existência é mais um “efeito secundário”. Quando utiliza (NÃO) IN e (NÃO) EXISTS,é realmente claro qual é a intenção da sua consulta. As uniões, por outro lado, podem ter múltiplos propósitos.
Utilizando um INNER JOIN, também pode ter múltiplas filas devolvidas para o mesmo valor se houver múltiplas correspondências na segunda tabela. Se quiser verificar a existência e se existe um valor, precisa de uma coluna da outra tabela, as uniões são preferidas.
Passos seguintes
- Pode encontrar mais dicas de T-SQL nesta vista geral.
- Long-time MVP Gail Shaw tem uma boa série sobre EXISTENTES vs IN vs JOINS. Se reinteressou na comparação EXISTS/IN versus JOINS, pode ler os seguintes posts de blog:
- IN vs INNER JOIN
- LEFT OUTER JOIN vs NOT EXISTS
- Dicas de Adesão ao SQL Server
- Tip:SQL Server Join Example
br>Lest Updated: 2019-05-13


h5>sobre o autor
 Koen Verbeeck é um profissional de BI, especializada na pilha BI da Microsoft com um amor particular pelo SSIS.
Koen Verbeeck é um profissional de BI, especializada na pilha BI da Microsoft com um amor particular pelo SSIS.Ver todas as minhas dicas
ul>>li>Mais Dicas de Desenvolvimento de Base de Dados…
br