Von: Koen Verbeeck | Aktualisiert: 2019-05-13 | Kommentare (6) | Verwandt: Mehr > T-SQL

Kostenloses MSSQLTips Webinar: Development Best Practices for SQL Server
In diesem Webinar erfahren Sie mehr über Best Practices bei der Entwicklung von SQL Server. Andy Warren wird seine langjährige Erfahrung weitergeben, um einige Hinweise zu geben, was für ihn am besten funktioniert hat und wie Sie etwas von diesem Wissen nutzen können.
Problem
Gibt es einen Unterschied zwischen der Verwendung des T-SQL-Operators IN oder des EXISTS-Operators in einer WHERE-Klausel, um nach bestimmten Werten zu filtern? Gibt es einen logischen Unterschied, einen Performance-Unterschied oder sind sie genau dasselbe? Und was ist mit NOT IN undNOT EXISTS?
Lösung
In diesem Tipp werden wir untersuchen, ob es Unterschiede zwischen demEXISTS – und dem IN -Operator gibt. Dies kann entweder logisch sein, d. h. sie verhalten sich unter bestimmten Umständen anders, oder leistungsmäßig, d. h. ob die Verwendung des einen Operators einen Leistungsvorteil gegenüber dem anderen hat. Für unsere Testabfragen verwenden wir dasAdventureWorks DW 2017.
SQL Server IN vs EXISTS
DerIN-Operator wird typischerweise verwendet, um eine Spalte nach einer bestimmten Liste von Werten zu filtern.Beispiel:
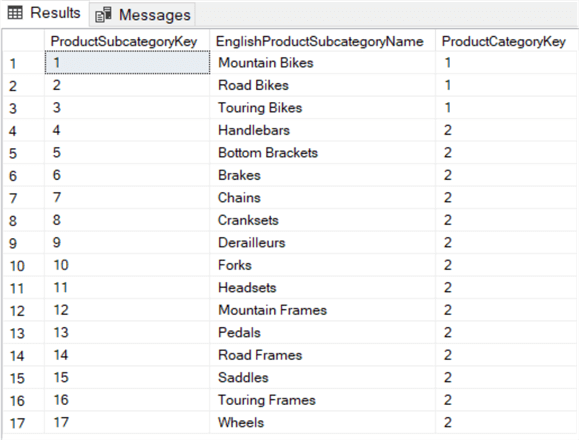
SELECT , ,FROM ..WHERE IN (1,2);
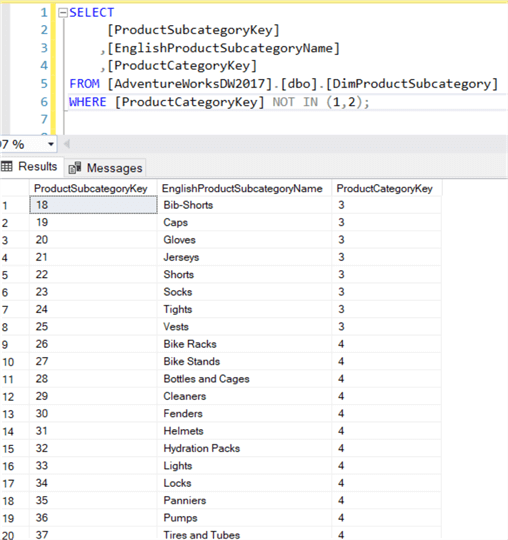
Diese Abfrage sucht nach allen Produktunterkategorien, die zu den Produktkategorien Fahrräder und Kategorien (ProductCategoryKey 1 und 2) gehören.
Sie können auch den IN-Operator verwenden, um die Werte in der Ergebnismenge der Subquery zu suchen:
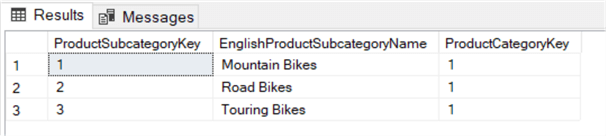
SELECT , ,FROM ..WHERE IN ( SELECT FROM . WHERE = 'Bikes' );
Diese Abfrage liefert alle Unterkategorien, die mit der Kategorie Fahrräder verknüpft sind.
Der Vorteil der Verwendung einer Subquery ist, dass die Abfrage weniger hart kodiert ist; wenn sich der ProductCategoryKey aus irgendeinem Grund ändert, wird die zweite Abfrage noch funktionieren, während die erste Abfrage plötzlich falsche Ergebnisse liefern könnte. Es ist wichtig, dass die Unterabfrage genau eine Spalte zurückgibt, damit der IN-Operator funktioniert.
DerEXISTS-Operator prüft nicht auf Werte, sondern auf die Existenz von Zeilen. Typischerweise wird eine Unterabfrage in Verbindung mit EXISTS verwendet. Es ist eigentlich egal, was die Unterabfrage zurückgibt, solange Zeilen zurückgegeben werden.
Diese Abfrage gibt alle Zeilen aus der Tabelle „ProductSubcategory“ zurück, weil die innere Unterabfrage Zeilen zurückgibt (die mit der äußeren Abfrage überhaupt nichts zu tun haben).
SELECT , ,FROM ..WHERE EXISTS ( SELECT 1/0 FROM . WHERE = 'Bikes' );
Wie Sie vielleicht bemerkt haben, hat die Unterabfrage 1/0 in der SELECT-Klausel. In einer normalen Abfrage würde dies einen Fehler beim Dividieren durch Null ergeben, aber innerhalb einer EXISTS-Klausel ist es völlig in Ordnung, da diese Division nie berechnet wird. Dies zeigt, dass es nicht wichtig ist, was die Unterabfrage zurückgibt, solange Zeilen zurückgegeben werden.
Um EXISTS auf sinnvollere Weise zu verwenden, können Sie eine korrelierte Unterabfrage verwenden.
In einer korrelierten Unterabfrage werden Werte aus der äußeren Abfrage mit Werten aus der inneren (Unter-)Abfrage gepaart. Dadurch wird effektiv geprüft, ob der Wert der äußeren Abfrage in der Tabelle existiert, die in der inneren Abfrage verwendet wird. Wenn wir zum Beispiel eine Liste aller Mitarbeiter zurückgeben wollen, die einen Verkauf getätigt haben, können wir die folgende Abfrage schreiben:
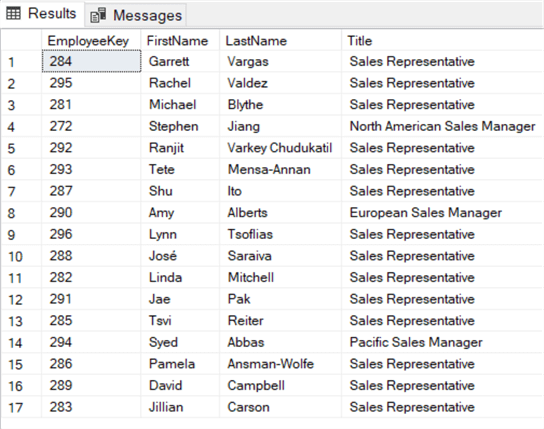
SELECT , , ,FROM .. eWHERE EXISTS ( SELECT 1 FROM dbo. f WHERE e. = f. );
In der WHERE-Klausel innerhalb der EXISTS-Unterabfrage korrelieren wir den Mitarbeiterschlüssel der äußeren Tabelle – DimEmployee – mit dem Mitarbeiterschlüssel der inneren Tabelle – FactResellerSales. Wenn der Mitarbeiterschlüssel in beiden Tabellen vorhanden ist, wird eine Zeile zurückgegeben und EXISTS gibt true zurück. Wenn der Mitarbeiterschlüssel in FactResellerSales nicht gefunden wird, gibt EXISTS false zurück und der Mitarbeiter wird aus den Ergebnissen ausgelassen:
Wir können die gleiche Logik mit dem IN-Operator implementieren:
SELECT , , ,FROM .. eWHERE IN ( SELECT FROM dbo. f );
Beide Abfragen geben die gleiche Ergebnismenge zurück, aber vielleicht gibt es einen zugrunde liegenden Leistungsunterschied? Vergleichen wir die Ausführungspläne.
Dies ist der Plan für EXISTS:
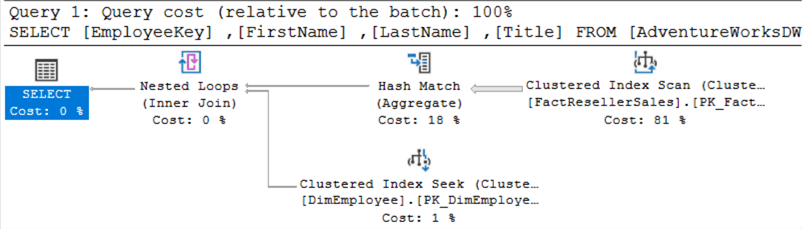
Dies ist der Plan für IN:
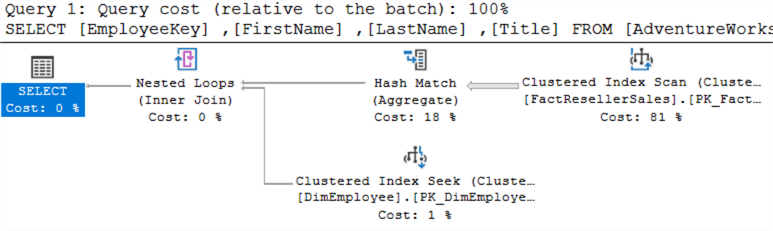
Sie sehen exakt gleich aus. Wenn Sie beide Abfragen gleichzeitig ausführen, können Sie sehen, dass sie die gleichen Kosten zugewiesen bekommen:
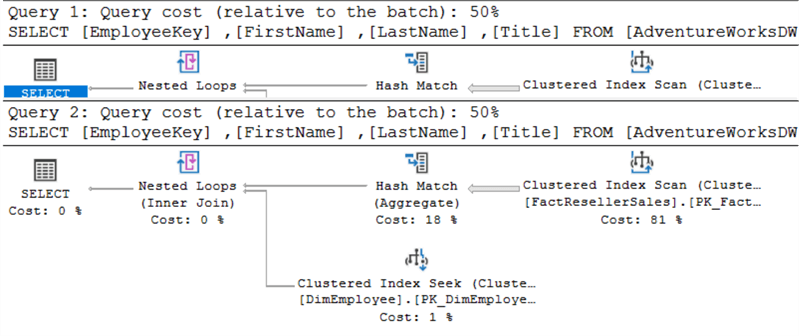
Der obere Ausführungsplan ist für EXISTS, der untere für IN.
Werfen wir einen Blick auf die IO-Statistiken (Sie können diese mit der Anweisung SET STATISTICS IO ON anzeigen). Auch hier ist alles genau gleich:

Es gibt also keinen nachweisbaren Performance-Unterschied und beide liefern die gleichen Ergebnismengen. Wann würden Sie das eine oder das andere verwenden? Hier sind ein paar Richtlinien:
- Wenn Sie eine kleine Liste mit statischen Werten haben (und die Werte nicht in einer Tabelle vorhanden sind), ist der IN-Operator vorzuziehen.
- Wenn Sie das Vorhandensein von Werten in einer anderen Tabelle prüfen müssen, ist der EXISTS-Operator vorzuziehen, da er die Absicht der Abfrage deutlich macht.
- Wenn Sie gegen mehr als eine einzelne Spalte prüfen müssen, können Sie EXISTS verwenden, da der IN-Operator nur die Prüfung für eine einzelne Spalte erlaubt.
Lassen Sie uns den letzten Punkt anhand eines Beispiels illustrieren. Im AdventureWorks Datawarehouse haben wir eine Dimension „Mitarbeiter“. Einige Mitarbeiter verwalten ein bestimmtes Verkaufsgebiet:
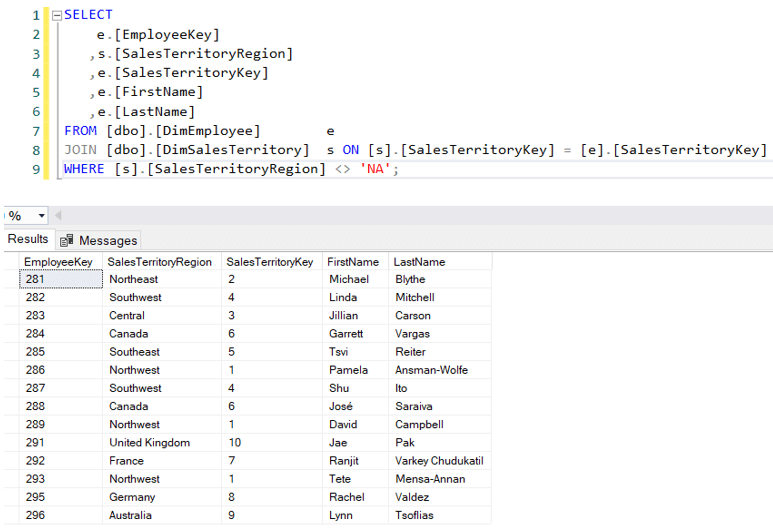
Nun ist es möglich, dass ein Mitarbeiter auch in anderen Gebieten Verkäufe tätigt.
Zum Beispiel hat Michael Blythe, der für die Region Nordost zuständig ist, in 4 verschiedenen Regionen verkauft:
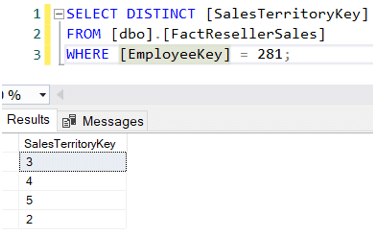
Angenommen, wir wollen jetzt nur die Umsatzbeträge für die Vertriebsgebietsleiter finden, aber nur für ihr eigenes Gebiet. Eine mögliche Abfrage könnte sein:
SELECT f. ,f. ,SUM()FROM . fWHERE EXISTS ( SELECT 1 FROM . e WHERE f. = e. AND f. = e. AND e. <> 11 -- the NA region )GROUP BY f. ,f.;
Das Ergebnis sieht wie folgt aus:
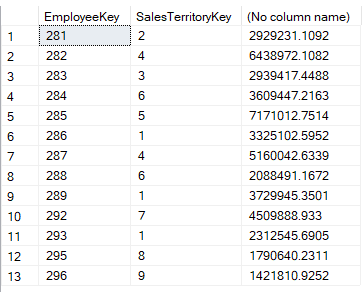
Innerhalb der EXISTS-Klausel rufen wir die Vertriebsgebietsmanager ab, indem wir alle Mitarbeiter herausfiltern, die mit der Region NA verknüpft sind. In der äußeren Abfrage erhalten wir alle Umsätze pro Vertriebsgebiet und Mitarbeiter, wobei der Mitarbeiter und das Gebiet in der inneren Abfrage gefunden werden. Wie Sie sehen, können wir mit EXISTS einfach auf mehrere Spalten prüfen, was mit IN nicht möglich ist.
SQL Server NOT IN vs NOT EXISTS
Indem wir den Operatoren den Operator NOT voranstellen, negieren wir die boolesche Ausgabe dieser Operatoren. Die Verwendung von NOT IN gibt zum Beispiel alle Zeilen mit einem Wert zurück, der nicht in einer Liste gefunden werden kann.
Es gibt allerdings einen Sonderfall: wenn NULL-Werte ins Spiel kommen. Wenn ein NULL-Wert in der Liste vorhanden ist, ist die Ergebnismenge leer!
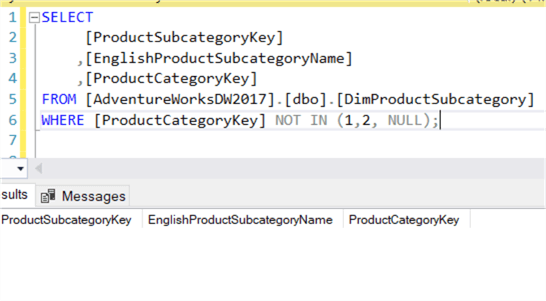
Das bedeutet, dass NOT IN unerwartete Ergebnisse liefern kann, wenn plötzlich ein NULL-Wert in der Ergebnismenge der Subquery auftaucht. NOT EXISTS hat dieses Problem nicht, da es keine Rolle spielt, was zurückgegeben wird. Wenn eine leere Ergebnismenge zurückgegeben wird, negiert NOT EXISTS dies, d. h. der aktuelle Datensatz wird nicht herausgefiltert:
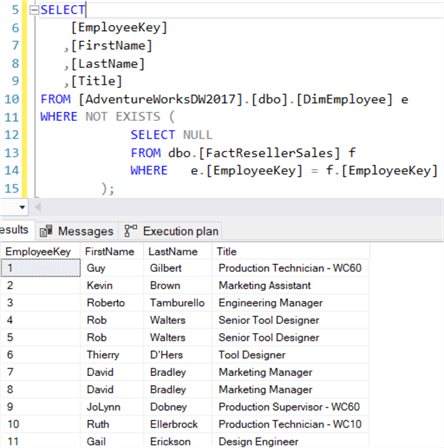
Die obige Abfrage gibt alle Mitarbeiter zurück, die keinen Verkauf getätigt haben. Logisch gesehen sind NOT IN und NOT EXISTS das Gleiche, d.h. sie geben die gleichen Ergebnismengen zurück, solange keine NULLS beteiligt sind. Gibt es einen Leistungsunterschied? Wiederum sind beide Abfragepläne gleich:
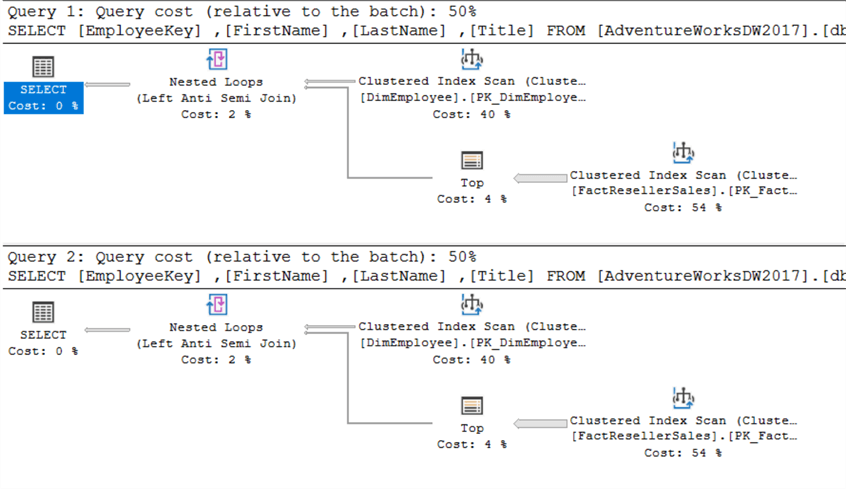
Das gleiche gilt für die IO-Statistiken:
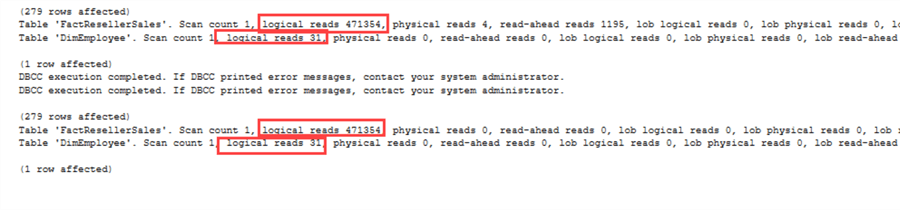
Es gibt allerdings einen Haken. Der EmployeeKey ist in FactResellerSales nicht-nullbar.Wie bereits gezeigt, kann NOT IN Probleme machen, wenn NULLs beteiligt sind. Wenn wirEmployeeKey so ändern, dass er nullbar ist, erhalten wir die folgenden Ausführungspläne:
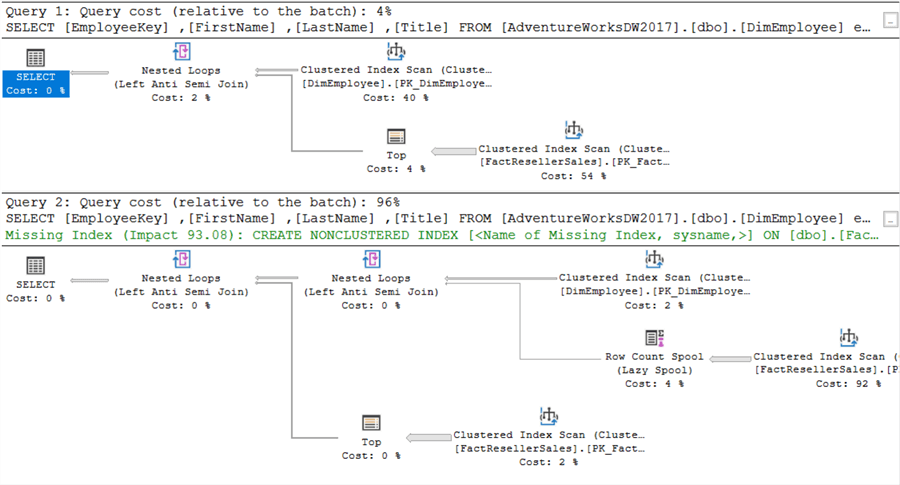
Ein deutlicher Unterschied diesmal! Da SQL Server nun auch NULL-Werte berücksichtigen muss, ändert sich der Ausführungsplan. Das sieht man auch an den IO-Statistiken:
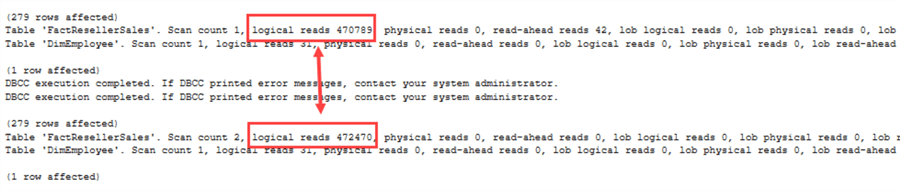
Jetzt gibt es einen tatsächlichen Performance-Unterschied zwischen NOT IN und NOT EXISTS.Wann sollte man welchen Operator verwenden? Einige Richtlinien:
- Die gleichen Richtlinien wie für IN und EXISTS können angewendet werden. Für die Prüfung gegen eine kleine statische Liste wird NOT IN bevorzugt. Für die Prüfung auf Existenz in einer anderen Tabelle? NOT EXISTS ist die bessere Wahl. Prüfen gegen mehrere Spalten, wiederNOT EXISTS.
- Wenn eine der Spalten nullbar ist, wird NOT EXISTS bevorzugt.
Verwendung von Joins anstelle von IN oder EXISTS
Die gleiche Logik kann auch mit Joins implementiert werden. Eine Alternative für IN undEXISTS ist einINNER JOIN, während einLEFT OUTER JOIN mit einer WHERE-Klausel, die auf NULL-Werte prüft, als Alternative für NOT IN und NOT EXISTS verwendet werden kann. Der Grund, warum sie nicht in diesem Tipp enthalten sind – obwohl sie genau die gleiche Ergebnismenge und den gleichen Ausführungsplan liefern könnten – ist, dass die Absicht eine andere ist. Mit IN und EXISTS prüfen Sie die Existenz von Werten in einer anderen Datensatzmenge. Bei Joins führen Sie die Ergebnismengen zusammen, d. h. Sie haben Zugriff auf alle Spalten der anderen Tabelle. Die Prüfung auf Existenz ist eher ein „Nebeneffekt“. Wenn Sie (NOT) IN und (NOT) EXISTS verwenden, ist wirklich klar, was die Absicht Ihrer Abfrage ist. Joins hingegen können mehrere Zwecke haben.
Bei Verwendung eines INNER JOIN können Sie auch mehrere Zeilen für denselben Wert zurückgeben lassen, wenn es mehrere Übereinstimmungen in der zweiten Tabelle gibt. Wenn Sie auf die Existenz eines Wertes prüfen wollen und dafür eine Spalte aus der anderen Tabelle benötigen, sind Joins vorzuziehen.
Nächste Schritte
- Weitere T-SQL-Tipps finden Sie in dieser Übersicht.
- Der langjährige MVP Gail Shaw hat eine schöne Serie über EXISTS vs IN vs JOINS. Wenn Sie sich für den Vergleich von EXISTS/IN vs. JOINS interessieren, können Sie die folgenden Blogbeiträge lesen:
- IN vs. INNER JOIN
- LEFT OUTER JOIN vs. NOT EXISTS
- SQL Server Join Tips
- Tipp:SQL Server Join Example
Letzte Aktualisierung: 2019-05-13


Über den Autor
 Koen Verbeeck ist ein BI-Profi, spezialisiert auf den Microsoft BI-Stack mit einer besonderen Vorliebe für SSIS.
Koen Verbeeck ist ein BI-Profi, spezialisiert auf den Microsoft BI-Stack mit einer besonderen Vorliebe für SSIS.Alle meine Tipps ansehen
- Mehr Tipps für Datenbankentwickler…