Da: Koen Verbeeck | Aggiornato: 2019-05-13 | Commenti (6) | Correlati: Altro > T-SQL

Free MSSQLTips Webinar: Migliori pratiche di sviluppo per SQL Server
Partecipa a questo webinar per imparare le migliori pratiche di sviluppo per SQL Server. Andy Warren condividerà i suoi molti anni di esperienza per dare alcune indicazioni su ciò che ha funzionato meglio per lui e come puoi utilizzare alcune di queste conoscenze.
Problema
C’è una differenza tra l’uso dell’operatore T-SQL IN o l’operatore EXISTS in una clausola WHERE per filtrare valori specifici? C’è una differenza logica, una differenza di prestazioni o sono esattamente la stessa cosa? E che dire di NOT IN eNOT EXISTS?
Soluzione
In questo suggerimento esamineremo se ci sono differenze tra l’operatoreEXISTS e l’operatore IN. Questo può essere sia logico, cioè si comportano diversamente in certe circostanze, sia in termini di prestazioni, cioè se usare un operatore ha un vantaggio in termini di prestazioni rispetto all’altro. Useremo l’AdventureWorks DW 2017 per le nostre query di prova.
QL Server IN vs EXISTS
L’operatore IN è tipicamente usato per filtrare una colonna per un certo elenco di valori:
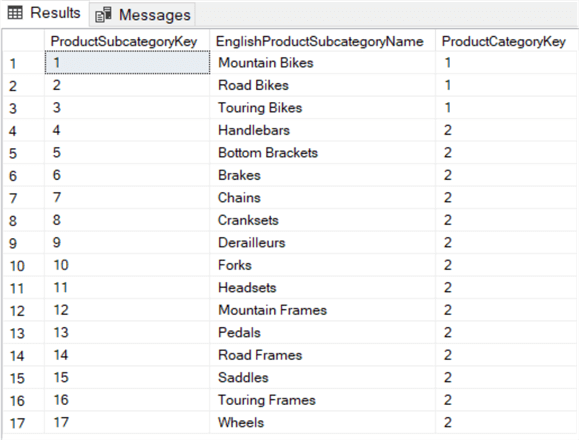
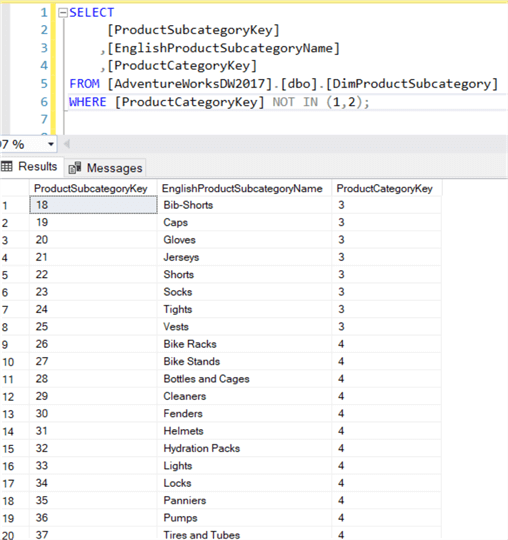
SELECT , ,FROM ..WHERE IN (1,2);
Questa query cerca tutte le sottocategorie di prodotti che appartengono alle categorie Bikes e Categories (ProductCategoryKey 1 e 2).
Puoi anche usare l’operatore IN per cercare i valori nel set di risultati dell’asubquery:
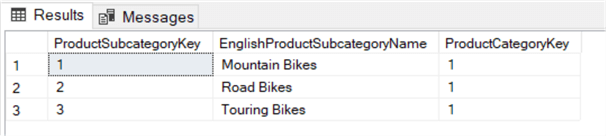
SELECT , ,FROM ..WHERE IN ( SELECT FROM . WHERE = 'Bikes' );
Questa query restituisce tutte le sottocategorie collegate alla categoria Bikes.
Il vantaggio di usare una subquery è che la query diventa meno hard-coded; se la ProductCategoryKey cambia per qualche motivo, la seconda query funzionerà ancora, mentre la prima query potrebbe improvvisamente restituire risultati errati. È importante che la subquery restituisca esattamente una colonna perché l’operatore IN funzioni.
L’operatoreEXISTS non controlla i valori, ma invece controlla l’esistenza di righe. Tipicamente, una subquery è usata insieme a EXISTS. In realtà non importa cosa restituisce la subquery, basta che vengano restituite le righe.
Questa query restituirà tutte le righe della tabella ProductSubcategory, perché la subquery interna restituisce le righe (che non sono affatto collegate alla query esterna).
SELECT , ,FROM ..WHERE EXISTS ( SELECT 1/0 FROM . WHERE = 'Bikes' );
Come avrete notato, la subquery ha 1/0 nella clausola SELECT. In un’interrogazione normale, questo restituirebbe un errore di divisione per zero, ma all’interno di una clausola EXISTS va perfettamente bene, poiché questa divisione non viene mai calcolata. Questo dimostra che non è importante cosa restituisce la subquery, basta che vengano restituite le righe.
Per usare EXISTS in un modo più significativo, potete usare una subquery correlata.In una subquery correlata, accoppiamo i valori della query esterna con quelli della (sub)query interna. Questo controlla effettivamente se il valore della query esterna esiste nella tabella usata nella query interna. Per esempio, se vogliamo restituire una lista di tutti i dipendenti che hanno effettuato una vendita, possiamo scrivere la seguente query:
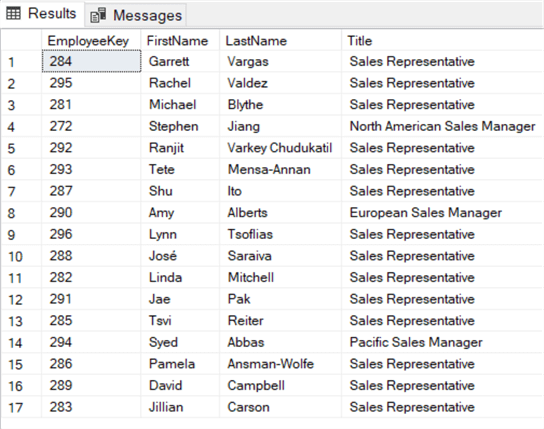
SELECT , , ,FROM .. eWHERE EXISTS ( SELECT 1 FROM dbo. f WHERE e. = f. );
Nella clausola WHERE all’interno della subquery EXISTS, correliamo la chiave dipendente della tabella esterna – DimEmployee – con la chiave dipendente della tabella interna – FactResellerSales. Se la chiave dipendente esiste in entrambe le tabelle, viene restituita una riga e EXISTS restituisce true. Se una chiave dipendente non viene trovata in FactResellerSales, EXISTS restituisce false e il dipendente viene omesso dai risultati:
Possiamo implementare la stessa logica usando l’operatore IN:
SELECT , , ,FROM .. eWHERE IN ( SELECT FROM dbo. f );
Entrambe le query restituiscono lo stesso set di risultati, ma forse c’è una differenza di performance sottostante? Confrontiamo i piani di esecuzione.
Questo è il piano per EXISTS:
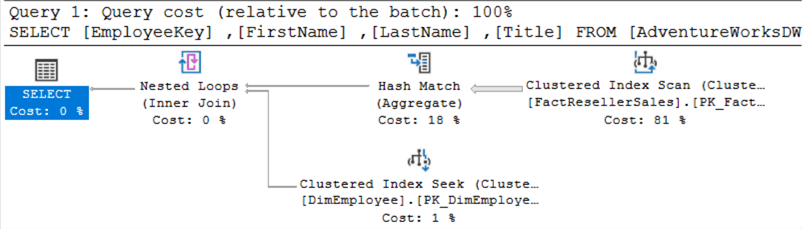
Questo è il piano per IN:
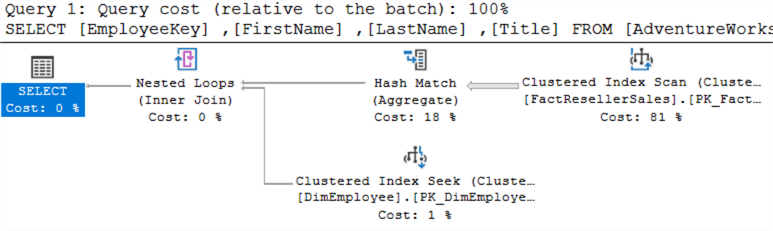
Sono esattamente uguali. Quando si eseguono entrambe le query allo stesso tempo, si può vedere che gli viene assegnato lo stesso costo:
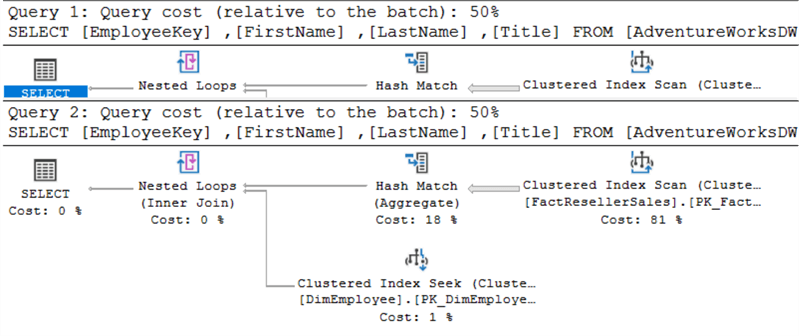
Il piano di esecuzione superiore è per EXISTS, quello inferiore per IN.
Diamo un’occhiata alle statistiche IO (potete mostrarle eseguendo il comando SET STATISTICS IO ON). Di nuovo, tutto è esattamente lo stesso:

Quindi, non c’è nessuna differenza di performance che possiamo provare ed entrambi restituiscono gli stessi set di risultati. Quando scegliereste di usare l’uno o l’altro? Ecco alcune linee guida:
- Se avete una piccola lista di valori statici (e i valori non sono presenti in qualche tabella), l’operatore IN è preferito.
- Se avete bisogno di controllare l’esistenza di valori in un’altra tabella, l’operatore EXISTS è preferito in quanto dimostra chiaramente l’intento della query.
- Se avete bisogno di controllare più di una singola colonna, potete usare EXISTS poiché l’operatore IN vi permette di controllare solo una singola colonna.
Illustriamo l’ultimo punto con un esempio. Nel datawarehouse di AdventureWorks, abbiamo una dimensione Employee. Alcuni dipendenti gestiscono uno specifico territorio di vendita:
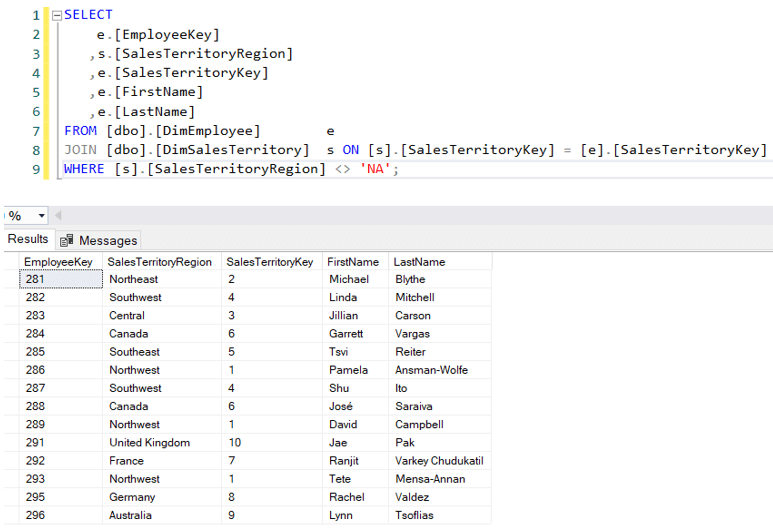
Ora, è possibile che un addetto alle vendite effettui vendite anche in altri territori.Per esempio, Michael Blythe – responsabile della regione Nord-Est – ha venduto in 4 regioni diverse:
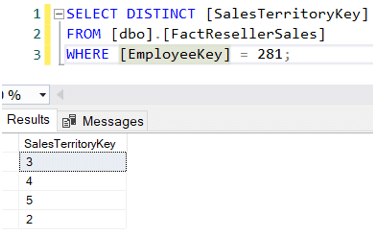
Immaginiamo ora di voler trovare solo gli importi delle vendite per i manager dei salesterritori, ma solo per la loro regione. Una possibile query potrebbe essere:
SELECT f. ,f. ,SUM()FROM . fWHERE EXISTS ( SELECT 1 FROM . e WHERE f. = e. AND f. = e. AND e. <> 11 -- the NA region )GROUP BY f. ,f.;
Il risultato è il seguente:
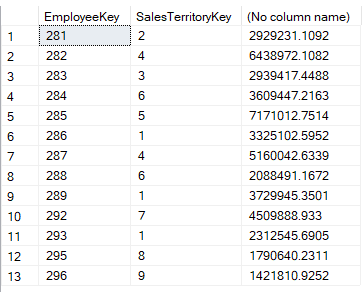
Nella clausola EXISTS, recuperiamo i manager dei territori di vendita filtrando tutti i dipendenti legati alla regione NA. Nella query esterna, otteniamo tutte le vendite per territorio di vendita e dipendente, dove il dipendente e il territorio sono trovati nella query interna. Come potete vedere, EXISTS ci permette di controllare facilmente colonne multiple, cosa che non è possibile con IN.
SQL Server NOT IN vs NOT EXISTS
Prefissando gli operatori con l’operatore NOT, neghiamo il risultato booleano di quegli operatori. Usando NOT IN, per esempio, restituirà tutte le righe con un valore che non può essere trovato in una lista.
C’è però un caso speciale: quando entrano in gioco i valori NULL. Se un valore NULL è presente nella lista, il set di risultati è vuoto!
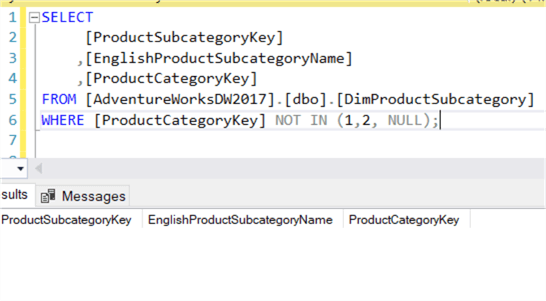
Questo significa che NOT IN può restituire risultati inaspettati se improvvisamente un valore NULL salta fuori nell’insieme dei risultati della subquery. NOT EXISTS non ha questo problema, poiché non importa cosa viene restituito. Se viene restituito un insieme di risultati vuoto, NOT EXISTS lo nega, il che significa che il record corrente non viene filtrato:
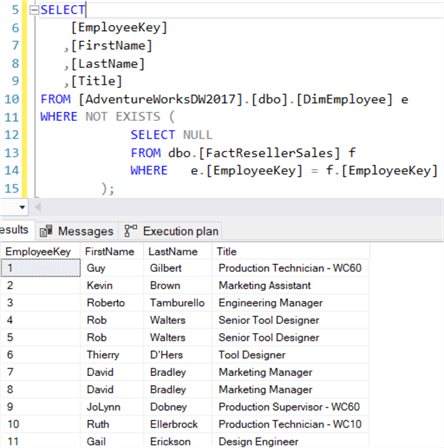
La query sopra riportata restituisce tutti i dipendenti che non hanno effettuato una vendita. Logicamente, NOT IN e NOT EXISTS sono la stessa cosa – nel senso che restituiscono gli stessi set di risultati – fino a quando i NULL non sono coinvolti. C’è una differenza di prestazioni? Di nuovo, entrambi i piani di query sono gli stessi:
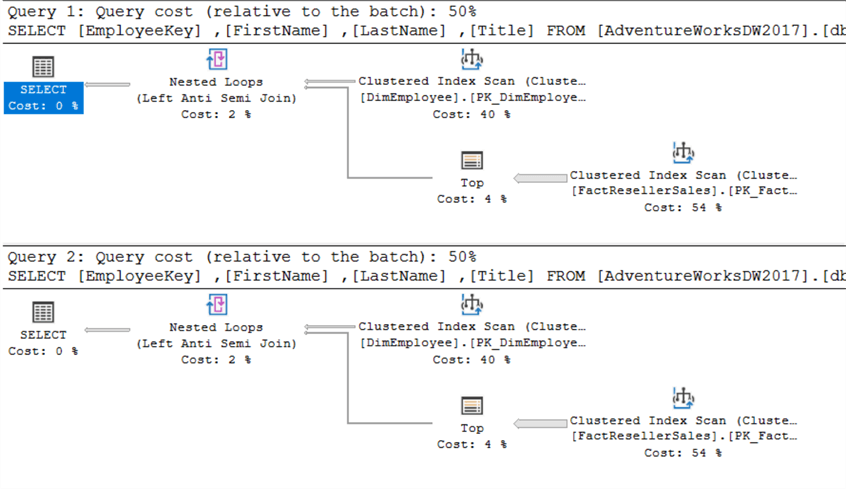
Lo stesso vale per le statistiche IO:
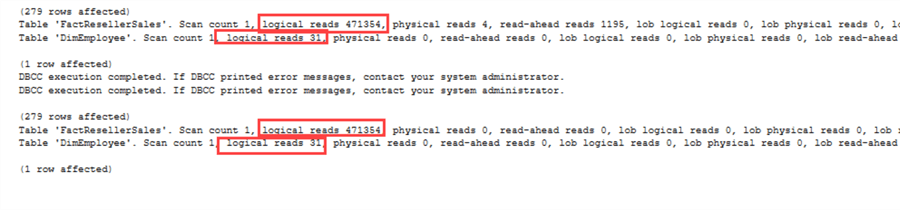
C’è però un problema. L’EmployeeKey è not-nullable in FactResellerSales. Come dimostrato prima, NOT IN può avere problemi quando sono coinvolti i NULL. Se cambiamoEmployeeKey per essere nullable, otteniamo i seguenti piani di esecuzione:
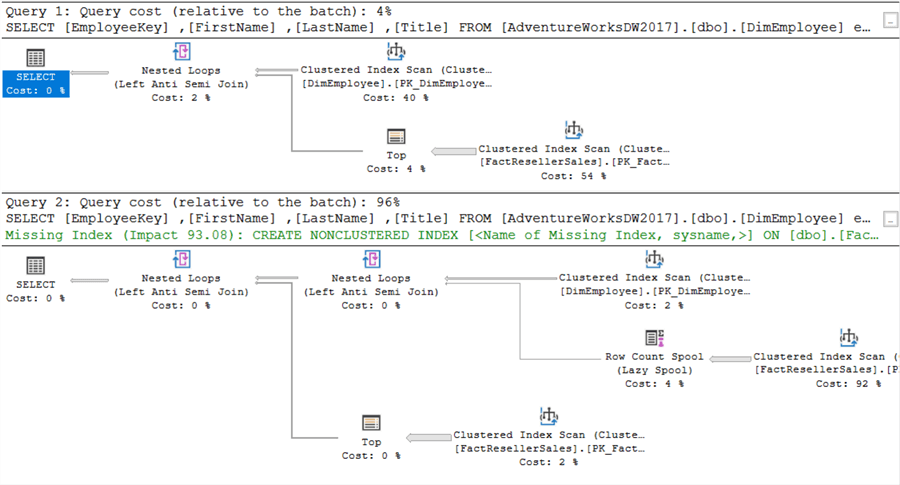
Questa volta c’è una bella differenza! Poiché SQL Server ora deve prendere in considerazione i valori NULL, il piano di esecuzione cambia. Lo stesso si può vedere nelle statistiche IO:
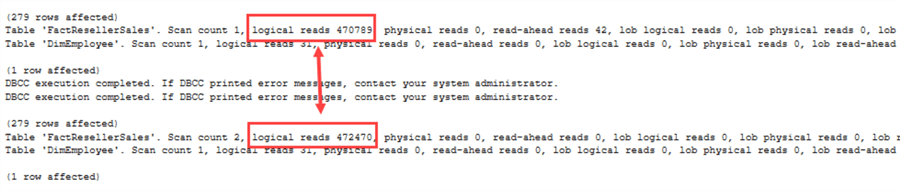
Ora c’è una reale differenza di performance tra NOT IN e NOT EXISTS.Quando usare quale operatore? Alcune linee guida:
- Si possono applicare le stesse linee guida di IN e EXISTS. Per il controllo di una piccola lista statica, NOT IN è preferito. Controllare l’esistenza in un’altra tabella? NOT EXISTS è la scelta migliore. Controllo di colonne multiple, di nuovoNOT EXISTS.
- Se una delle colonne è nulla, NOT EXISTS è preferito.
Utilizzare le giunzioni invece di IN o EXISTS
La stessa logica può essere implementata anche con le giunzioni. Un’alternativa per IN ed EXISTS è unaINNER JOIN, mentre unaLEFT OUTER JOIN con una clausola WHERE che controlla i valori NULL può essere usata come alternativa per NOT IN e NOT EXISTS. La ragione per cui non sono inclusi in questo suggerimento – anche se potrebbero restituire lo stesso identico set di risultati e lo stesso piano di esecuzione – è perché l’intento è diverso. Con IN e EXISTS, si controlla l’esistenza di valori in un altro record set. Con i join si uniscono i set di risultati, il che significa che si ha accesso a tutte le colonne dell’altra tabella. Il controllo dell’esistenza è più un “effetto collaterale”. Quando usate (NOT) IN e (NOT) EXISTS, è davvero chiaro quale sia l’intento della vostra query. Le giunzioni, d’altra parte, possono avere molteplici scopi.
Utilizzando una INNER JOIN, puoi anche avere più righe restituite per lo stesso valore se ci sono più corrispondenze nella seconda tabella. Se volete controllare l’esistenza e se un valore esiste avete bisogno di una colonna dell’altra tabella, le join sono preferite.
Passi successivi
- Potete trovare altri suggerimenti T-SQL in questa panoramica.
- Long-time MVP Gail Shaw ha una bella serie su EXISTS vs IN vs JOINS. Se sei interessato a confrontare EXISTS/IN rispetto alle JOINS, puoi leggere i seguenti post del blog:
- IN vs INNER JOIN
- LEFT OUTER JOIN vs NOT EXISTS
- Suggerimenti su SQL Server Join
- Tip:SQL Server Join Example
Ultimo aggiornamento: 2019-05-13


Informazioni sull’autore
 Koen Verbeeck è un professionista della BI, specializzato nello stack Microsoft BI con un amore particolare per SSIS.
Koen Verbeeck è un professionista della BI, specializzato nello stack Microsoft BI con un amore particolare per SSIS.Vedi tutti i miei consigli
- Altri consigli per sviluppatori di database…