By: Koen Verbeeck | Updated: 2019-05-13 | Komentarze (6) | Powiązane: More > T-SQL

Darmowe webinarium MSSQLTips: Development Best Practices for SQL Server
Weź udział w tym webinarium, aby dowiedzieć się o najlepszych praktykach rozwoju dla SQL Server. Andy Warren podzieli się swoim wieloletnim doświadczeniem, aby dać kilka wskazówek na temat tego, co najlepiej sprawdziło się w jego przypadku i jak możesz wykorzystać część tej wiedzy.
Problem
Czy istnieje różnica między użyciem operatora T-SQL IN lub operatora EXISTS w klauzuli WHERE do filtrowania określonych wartości? Czy jest to różnica logiczna, wydajnościowa czy też są one dokładnie takie same? A co z NOT IN iNOT EXISTS?
Rozwiązanie
W tym poradniku sprawdzimy czy są jakieś różnice pomiędzy operatoremEXISTS a IN. Mogą to być zarówno różnice logiczne, tzn. że zachowują się one inaczej w pewnych okolicznościach, jak i wydajnościowe, tzn. czy użycie jednego z operatorów ma przewagę wydajnościową nad drugim. Do naszych zapytań testowych użyjemy narzędziaAdventureWorks DW 2017.
SerwerSQL IN vs EXISTS
OperatorIN jest zazwyczaj używany do filtrowania kolumny dla pewnej listy wartości.Na przykład:
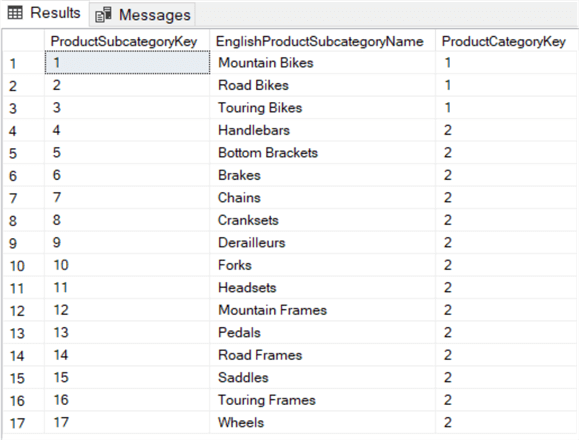
SELECT , ,FROM ..WHERE IN (1,2);
To zapytanie wyszukuje wszystkie podkategorie produktów, które należą do productcategories Rowery i Kategorie (ProductCategoryKey 1 i 2).
Operator IN można również wykorzystać do wyszukiwania wartości w zbiorze wyników asubquery:
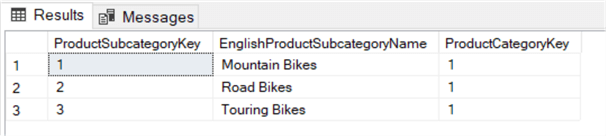
SELECT , ,FROM ..WHERE IN ( SELECT FROM . WHERE = 'Bikes' );
To zapytanie zwraca wszystkie podkategorie powiązane z kategorią Rowery.
Zaletą użycia podzapytania jest to, że zapytanie staje się mniej skomplikowane; jeśli ProductCategoryKey zmieni się z jakiegoś powodu, drugie zapytanie będzie nadal działać, podczas gdy pierwsze zapytanie może nagle zwrócić nieprawidłowe wyniki. Ważne jest, aby podzapytanie zwracało dokładnie jedną kolumnę, aby operator IN działał.
OperatorEXISTS nie sprawdza wartości, ale zamiast tego sprawdza istnienie wierszy. Zazwyczaj podzapytanie jest używane w połączeniu z EXISTS. W rzeczywistości nie ma znaczenia, co zwraca podzapytanie, tak długo, jak wiersze są zwracane.
To zapytanie zwróci wszystkie wiersze z tabeli ProductSubcategory, ponieważ pierwsze podzapytanie zwraca wiersze (które nie są w ogóle związane z zewnętrznym zapytaniem).
SELECT , ,FROM ..WHERE EXISTS ( SELECT 1/0 FROM . WHERE = 'Bikes' );
Jak można zauważyć, podzapytanie ma 1/0 w klauzuli SELECT. W normalnym zapytaniu, zwróciłoby to błąd dzielenia przez zero, ale wewnątrz klauzuli EXISTS jest idealnie w porządku, ponieważ ten podział nigdy nie jest obliczany. Pokazuje to, że nie jest ważne, co podzapytanie zwraca, tak długo jak wiersze są zwracane.
Aby użyć EXISTS w bardziej znaczący sposób, możesz użyć skorelowanego podzapytania.
W skorelowanym podzapytaniu, parujemy wartości z zewnętrznego zapytania z wartościami z poprzedniego (pod)zapytania. To efektywnie sprawdza, czy wartość z zewnętrznego zapytania istnieje w tabeli użytej w wewnętrznym zapytaniu. Na przykład, jeśli chcemy zwrócić listę wszystkich pracowników, którzy dokonali sprzedaży, możemy napisać następujące zapytanie:
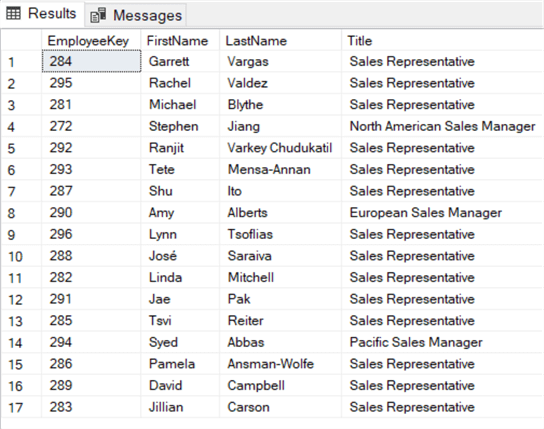
SELECT , , ,FROM .. eWHERE EXISTS ( SELECT 1 FROM dbo. f WHERE e. = f. );
W klauzuli WHERE wewnątrz podzapytania EXISTS, korelujemy klucz pracownika tabeli zewnętrznej – DimEmployee – z kluczem pracownika tabeli wewnętrznej – FactResellerSales. Jeśli klucz pracownika istnieje w obu tabelach, zwracany jest wiersz, a EXISTS zwraca wartość true. Jeśli klucz pracownika nie zostanie znaleziony w FactResellerSales, EXISTS zwróci false, a pracownik zostanie pominięty w wynikach:
Tę samą logikę możemy zaimplementować używając operatora IN:
SELECT , , ,FROM .. eWHERE IN ( SELECT FROM dbo. f );
Oba zapytania zwracają ten sam zestaw wyników, ale może istnieje jakaś podstawowa różnica w wydajności? Porównajmy plany wykonania.
To jest plan dla EXISTS:
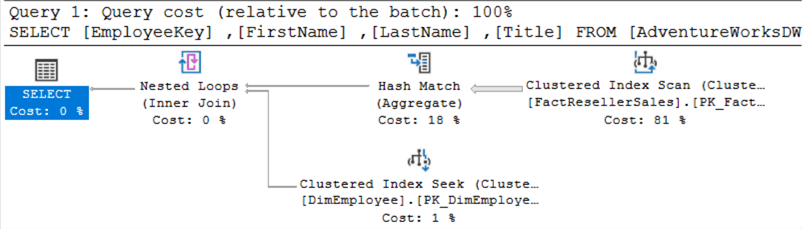
To jest plan dla IN:
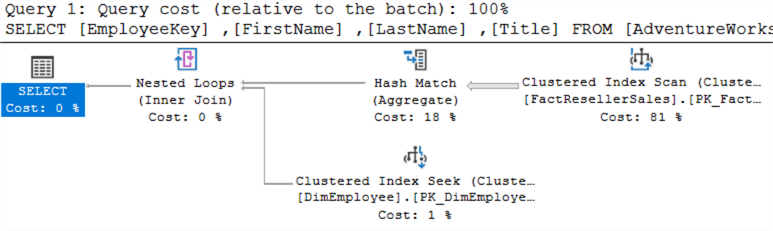
Wyglądają one dokładnie tak samo. Podczas wykonywania obu zapytań w tym samym czasie, można zauważyć, że otrzymują one ten sam koszt:
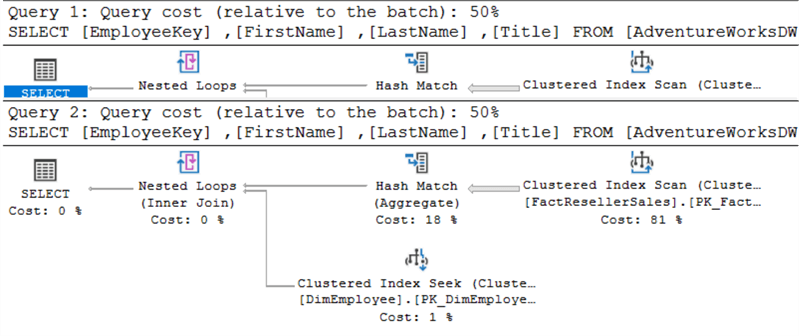
Górny plan wykonania jest dla EXISTS, dolny dla IN.
Spójrzmy na statystyki IO (można je wyświetlić uruchamiając polecenie SET STATISTICS IO ON). Ponownie, wszystko jest dokładnie takie samo:

Więc, nie ma różnicy w wydajności, którą możemy udowodnić i oba zwracają te same zestawy wyników. Kiedy zdecydowałbyś się użyć jednego lub drugiego? Oto kilka wskazówek:
- Jeśli masz małą listę statycznych wartości (i wartości te nie są obecne w jakiejś tabeli), preferowany jest operator IN.
- Jeśli potrzebujesz sprawdzić istnienie wartości w innej tabeli, preferowany jest operator EXISTS, ponieważ jasno pokazuje on intencje zapytania.
- Jeśli potrzebujesz sprawdzić więcej niż jedną kolumnę, możesz użyć EXISTS, ponieważ operator IN pozwala na sprawdzenie tylko jednej kolumny.
Zilustrujmy ostatni punkt przykładem. W hurtowni danych AdventureWorks mamy wymiar Employee. Niektórzy pracownicy zarządzają określonym terytorium sprzedaży:
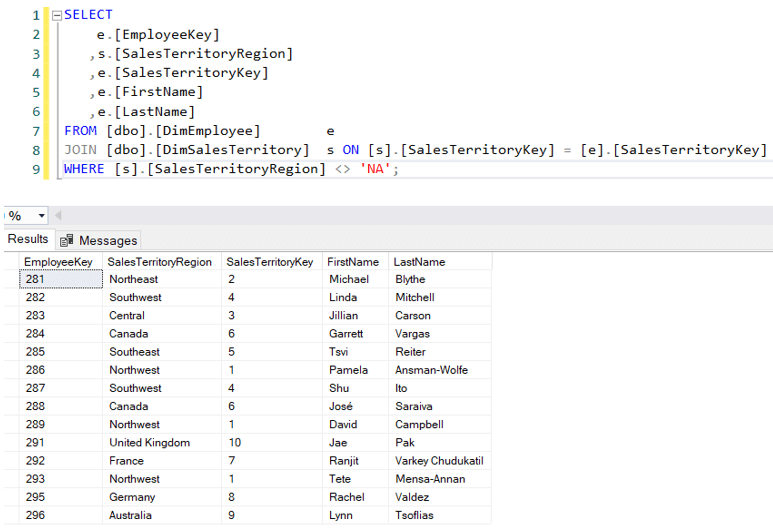
Możliwe jest, że dany pracownik sprzedaży prowadzi sprzedaż również na innych terytoriach, np. Michael Blythe – odpowiedzialny za region Northeast – prowadził sprzedaż w 4 różnych regionach:
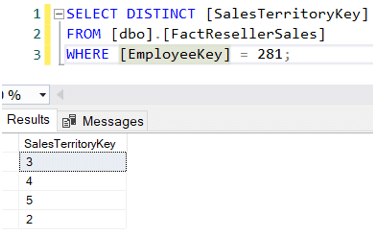
Załóżmy, że teraz chcemy znaleźć kwoty sprzedaży tylko dla menedżerów salesterritory, ale tylko dla ich własnego regionu. Możliwe zapytanie mogłoby wyglądać następująco:
SELECT f. ,f. ,SUM()FROM . fWHERE EXISTS ( SELECT 1 FROM . e WHERE f. = e. AND f. = e. AND e. <> 11 -- the NA region )GROUP BY f. ,f.;
Wynik jest następujący:
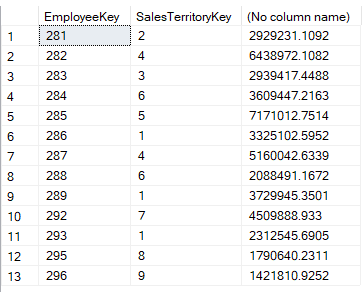
Wewnątrz klauzuli EXISTS, pobieramy menedżerów terytoriów sprzedaży poprzez odfiltrowanie wszystkich pracowników powiązanych z regionem NA. W zewnętrznym zapytaniu, pobieramy wszystkie sprzedaże na terytorium sprzedaży i pracownika, gdzie pracownik i terytorium jest znalezione w wewnętrznym zapytaniu. Jak widać, EXISTS pozwala nam na łatwe sprawdzenie wielu kolumn, co nie jest możliwe w przypadku IN.
SQL Server NOT IN vs NOT EXISTS
Poprzez poprzedzenie operatorów operatorem NOT, negujemy wynik Boolean tych operatorów. Na przykład użycie NOT IN zwróci wszystkie wiersze z wartością, której nie można znaleźć na liście.
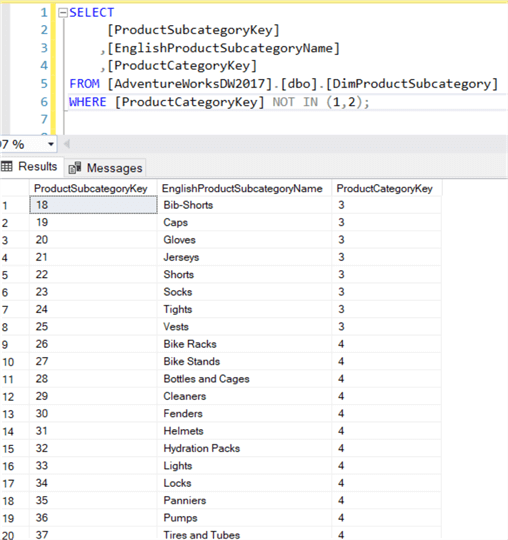
Jest jednak jeden szczególny przypadek: kiedy wartości NULL wchodzą w grę. Jeśli wartość NULL jest obecna na liście, zestaw wyników jest pusty!
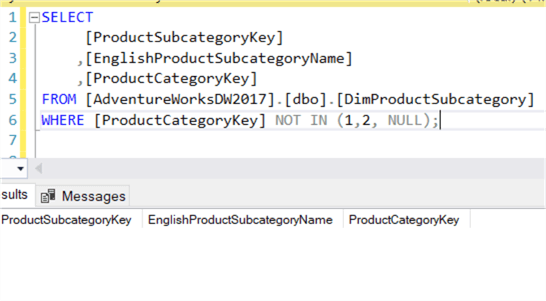
To oznacza, że NOT IN może zwrócić nieoczekiwane wyniki, jeśli nagle w wyniku podzapytania pojawi się wartość NULL. NOT EXISTS nie ma tego problemu, ponieważ nie ma znaczenia, co zostanie zwrócone. Jeśli zwrócony zostanie pusty zestaw wyników, NOT EXISTS zaneguje to, co zostało zwrócone, co oznacza, że bieżący rekord nie zostanie odfiltrowany:
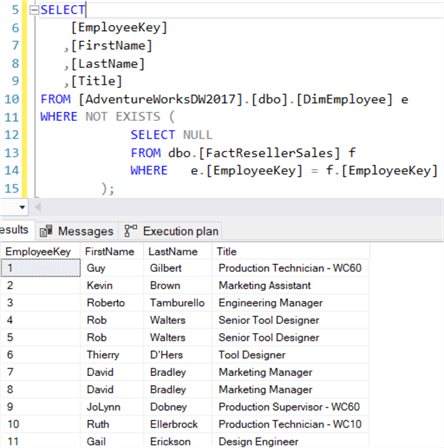
Powyższe zapytanie zwraca wszystkich pracowników, którzy nie dokonali sprzedaży. Logicznie rzecz biorąc, NOT IN i NOT EXISTS są takie same – co oznacza, że zwracają te same zestawy wyników – tak długo, jak NULLS nie są zaangażowane. Czy istnieje różnica w wydajności? Ponownie, oba plany zapytań są takie same:
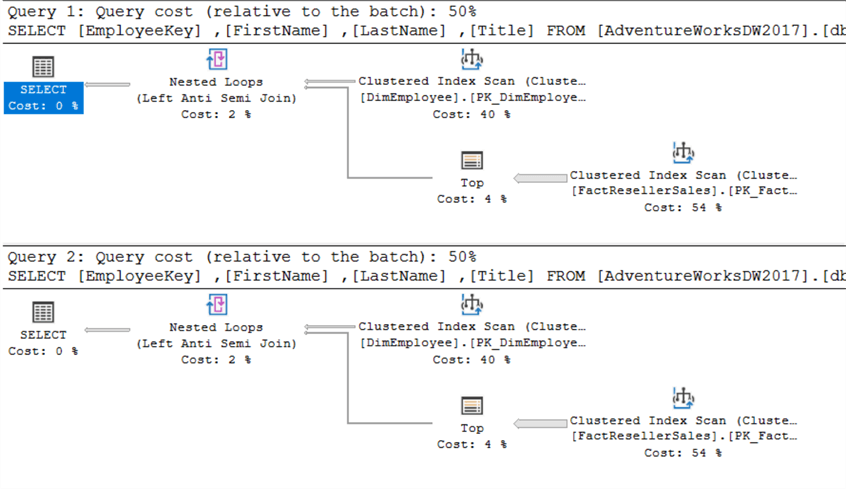
To samo dotyczy statystyk IO:
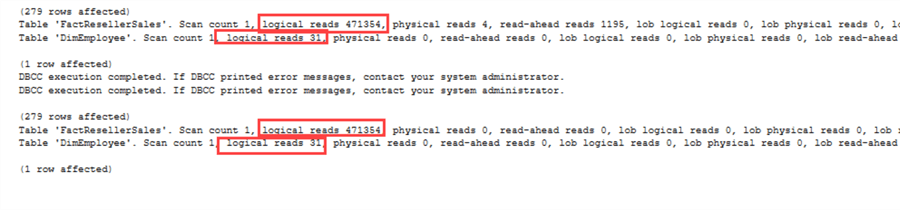
Jest jednak jeden problem. EmployeeKey jest not-nullable w FactResellerSales.Jak pokazano wcześniej, NOT IN może mieć problemy, gdy NULL są zaangażowane. Jeśli zmienimy kluczEmployeeKey na nullable, otrzymamy następujące plany wykonania:
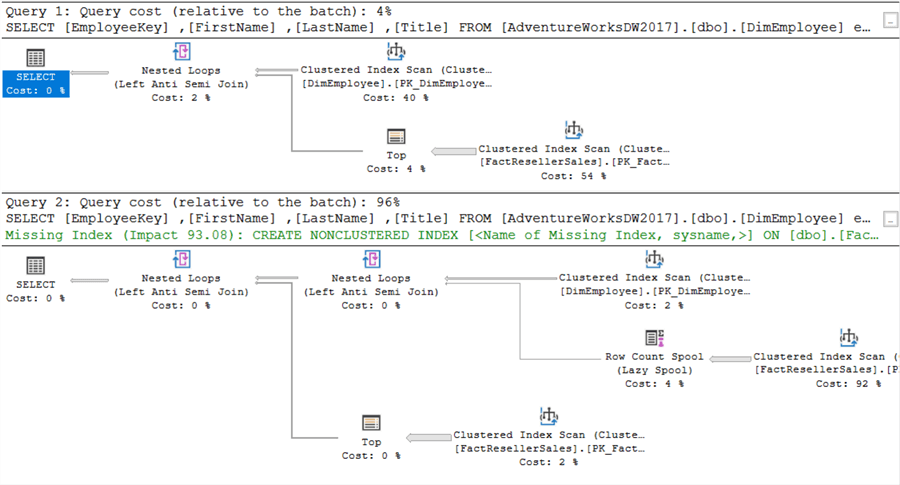
Całkiem spora różnica tym razem! Ponieważ SQL Server musi teraz brać pod uwagę wartości NULL, plan wykonania ulega zmianie. To samo widać w statystykach IO:
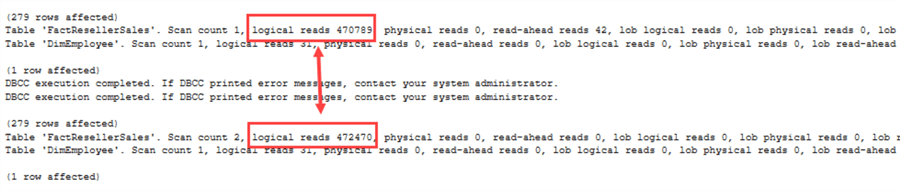
Teraz widać rzeczywistą różnicę wydajności pomiędzy NOT IN a NOT EXISTS.Kiedy użyć którego operatora? Kilka wskazówek:
- Można zastosować te same wytyczne co dla IN i EXISTS. W przypadku sprawdzania względem małej listy statycznej, preferowany jest operator NOT IN. Sprawdzanie istnienia w innej tabeli? NOT EXISTS jest lepszym wyborem. Sprawdzanie na podstawie wielu kolumn, ponownieNOT EXISTS.
- Jeśli jedna z kolumn jest nullable, NOT EXISTS jest preferowane.
Używanie złączeń zamiast IN lub EXISTS
Tę samą logikę można zaimplementować również za pomocą złączeń. Alternatywą dla IN iEXISTS jestINNER JOIN, podczas gdyLEFT OUTER JOIN z klauzulą WHERE sprawdzającą wartości NULL może być użyte jako alternatywa dla NOT IN i NOT EXISTS. Powodem, dla którego nie zostały one uwzględnione w tym poradniku – nawet jeśli mogą zwrócić dokładnie taki sam zestaw wyników i plan wykonania – jest to, że ich intencja jest inna. Za pomocą IN i EXISTS sprawdzamy istnienie wartości w innym zbiorze rekordów. W przypadku złączenia, łączymy zestawy wyników, co oznacza, że mamy dostęp do wszystkich kolumn drugiej tabeli. Sprawdzanie istnienia jest bardziej „efektem ubocznym”. Kiedy używasz (NOT) IN i (NOT) EXISTS, jest naprawdę jasne, jaki jest cel twojego zapytania. Z drugiej strony, złączenia mogą mieć wiele celów.
Używając INNER JOIN, możesz również mieć wiele wierszy zwróconych dla tej samej wartości, jeśli istnieje wiele dopasowań w drugiej tabeli. Jeśli chcesz sprawdzić, czy dana wartość istnieje i potrzebujesz kolumny z drugiej tabeli, preferowane są złączenia.
Następne kroki
- Więcej wskazówek T-SQL znajdziesz w tym przeglądzie.
- Długoletni MVP Gail Shaw ma fajną serię na temat EXISTS vs IN vs JOINS. Jeśli jesteś zainteresowany porównaniem EXISTS/IN vs JOINS, możesz przeczytać następujące posty:
- IN vs INNER JOIN
- LEFT OUTER JOIN vs NOT EXISTS
- SQL Server Join Tips
- Tip:SQL Server Join Example
Ostatnia aktualizacja: 2019-05-13


O autorze
 Koen Verbeeck jest profesjonalistą w dziedzinie BI, specjalizuje się w stosie Microsoft BI ze szczególnym zamiłowaniem do SSIS.
Koen Verbeeck jest profesjonalistą w dziedzinie BI, specjalizuje się w stosie Microsoft BI ze szczególnym zamiłowaniem do SSIS.Zobacz wszystkie moje porady
- Więcej porad dla programistów baz danych…